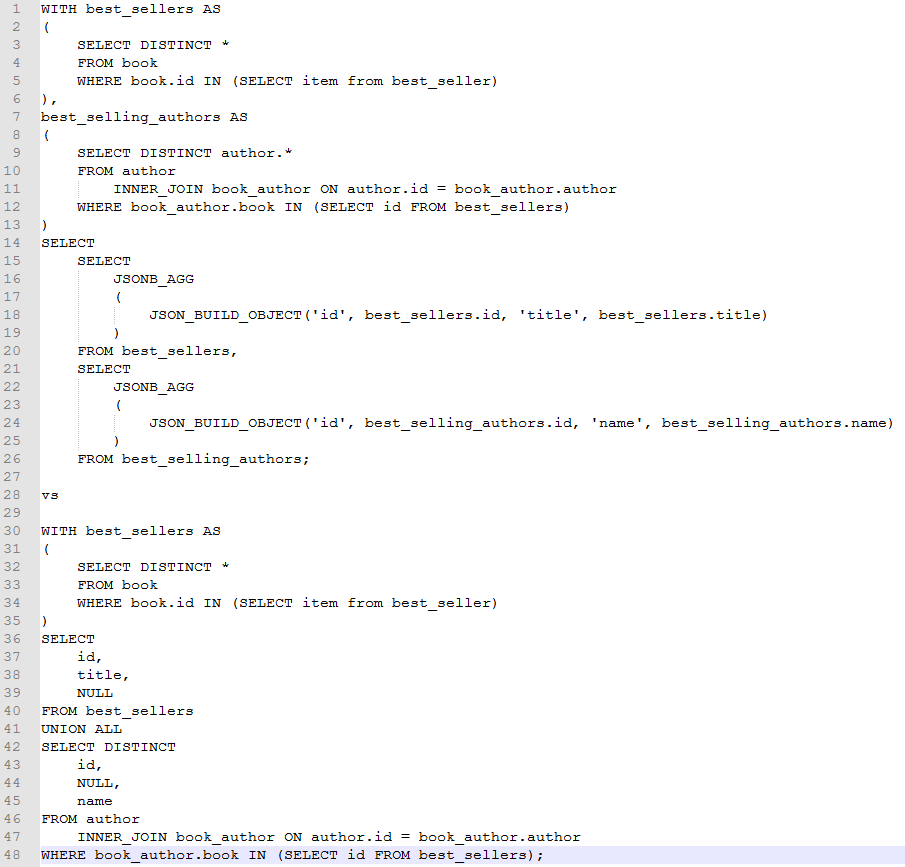
I am currently working on a project that involves writing stored functions in PostgreSQL. Typically the goal is one SQL query that returns all the data needed by a particular web page. At first I approached this from an Object Oriented perspective with a focus on minimizing redundant data. This led me down the path of JSONB_AGG and custom Hibernate UserTypes. The queries I wrote with this method were difficult to tune and not always performant. Also when the user needs changed, it was burdensome to readdress the UserType(s) and restructure the query. From the web-client perspective, I was getting exactly what I wanted (aside from performance in some cases).
As time went on I changed my initial mindset when developing these stored functions. I now think of it from a SQL perspective first. This means I return a table of primitive types. Some of which will be redundant information. This has led me towards using UNION ALL and boolean/text columns that specify the type of data in that row. Using this method, I have actually not yet had to do any performance tuning. The SQL is straightforward to write, and I don’t need to make custom UserTypes. When user needs change, I just alter the columns or add a new union. I do have to parse the result set into objects at some point, but that has been quick and easy so far. I have been doing it on the client side, but if there is a static contract it would need to be done on the server side.
The difference in development time has been quite noticeable as well. Previously, I had spent as much as an entire work day getting a complicated stored function to produce something that directly translates into a set of model objects. I’ve not had the result set method take me longer than 2 hours yet, despite some of the query requirements being more complicated (including some queries that required a recursive CTE).