

Mutable state gets a bad rap when you talk to pure functional programmers. I don’t think mutable state is inherently a problem, but it does have an effect on your ability to understand a program. So let’s look at what happens when you introduce a mutable reference into a programming language.
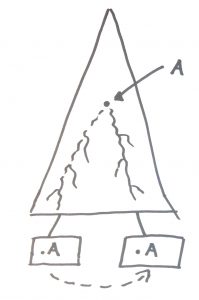
The problem as I see it is that if you introduce some sort of mutable reference “A” into a program, then you’ll get scenarios like the above diagram indicates. “A” starts its life someplace in the call tree and then it travels down through function calls until it reaches a point where it’s used. This creates a situation where the way the box on the right behaves is dependent on an invisible connection to the way that the box behaves on the left. The situation can get worse.
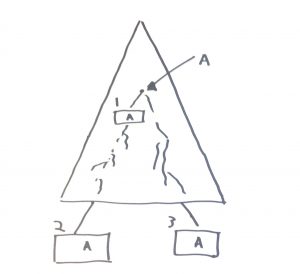
Here’s the same situation except the mutable reference “A” is also somehow involved at point 1 in the diagram.
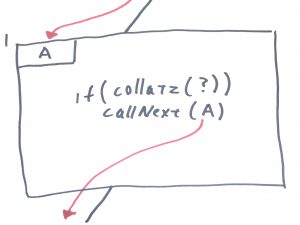
Point 1 passes the reference “A” down to the next function in the tree, but it does so in a conditional way. And as we saw in the previous post, it can get arbitrarily hard to understand when we’re going to call the next function.
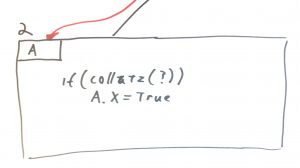
Point 2 in the diagram shows a similar problem. We’re setting the value “X” to be true. But we’re doing it in a conditional way. Understanding the nature of “A” now depends on understanding what happens at point 2, but you also have to search all previous function calls because you may encounter a situation like the one at point 1, above.
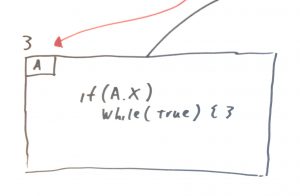
Finally, the punchline at point 3. Point 3 shows us that our program is going to potentially run forever in an unproductive loop. However, this is dependent on “A” and further more it is dependent on the value of “X” that “A” has within it. Where does this value get set? It happens at point 2 … maybe. Also when do we get to point 2? Well, we’ll get there whenever point 1 allows us to get there. And does anyone know what scenarios point 1 allows us to get to point 2? No, nobody knows.
For this situation, we can probably guess that things will work out in a comprehensible fashion. But in the real world we rarely encounter functions that have well known behaviors (collatz will probably halt, but who knows what the method DoManagementComponent7 will do). So things can get arbitrarily difficult to understand by just looking at the source code.
Having mutable references means that static information isn’t always enough to understand a program. You may require a debugger.
Basically, the worst case scenario is that you need a debugging break point at every function call that takes a reference to your “A” object. Make sure you ignore functions that have an object of the same type of “A”, but a different reference. Also consider that one function might sometimes be used with the “A” we care about and sometimes used at a different location with a different reference. Also consider that a function might conditionally get the reference we care about even if it is being called in the same place in the call tree.
void UseTheA( A a )
{
if ( someCondition )
a.X = true;
}
// This function is never called with the 'a' we care about,
// so we can ignore it.
void Other( A a )
{
a.X = true;
// Oh no. UseTheA sometimes gets someone else's 'a'.
// We have to sometimes ignore it in the debugger.
UseTheA( a );
}
void SomeCode()
{
var a = new A();
// The 'a' we care about is used here,
// so we need to debug that function.
UseTheA( a );
// We don't care about this 'a' though ... but only sometimes.
// So we need to sometimes debug this function.
UseTheA( someOtherCondition ? a : new A() );
ImportantAUsage( a );
}Things however can get worse if you have mutable references that you are allowed to share. We’ll look at that next time.
Build awesome things for fun.
Check out our current openings for your chance to make awesome things with creative, curious people.
You Might Also Like