

Bronze, Silver, Gold. If you’re familiar with modern lakehouse design, you will recognize this pattern called the medallion architecture. Raw data is ingested into Bronze. Cleaned and conformed records get staged into Silver. Curation applies business rules and turns Silver data into analytics-ready datasets that land in Gold. Clean, intuitive, works great.
But what if you want to share your Gold data with someone outside your governance context? What if your Gold data is still proprietary, sensitive, or otherwise not directly shareable?
A New Pressure, Not an Old Oversight
The medallion architecture was designed for a world where data platforms were primarily reporting systems: internal analysts, broadly similar access profiles, and one organization’s data feeding that same organization’s dashboards. It works well in that world.
What’s changed is that data platforms have started crossing a maturity threshold. More enterprises now have valuable data products in Gold — curated, trusted, actively used to run business functions — and with that comes a new question the pattern wasn’t built to answer: how do we share the value of this data externally without giving external consumers direct access to Gold when requirements dictate we can’t?
Sometimes “externally” means a partner organization. Sometimes it means a different internal business unit with its own data governance boundary. The pressure is the same either way: the platform’s products are mature enough to be worth sharing, but the data is sensitive enough that direct access isn’t an option.
We are working on a project where the operational data as is can’t even be shared with others in the same organization due to regulatory requirements. Our plan is to put mechanisms in place to sanitize the data so it can be shared with the larger organization.
We’ve seen this need pop up in some of our clients in regulated sectors—life sciences, government, financial services—where operational data contexts are deliberately isolated. The Gold layer may contain PHI, competitive IP, or otherwise controlled information that can’t flow unmodified to a shared layer. But the business need for cross-context analytics—benchmarking, aggregate reporting, health metrics, analytics—is real and legitimate.
The standard response tends to be one of two approaches: either lock the data down and the cross-context use case never gets realized or build an ad hoc export process that meets the current needs. Neither is a satisfactory business outcome or sustainable long term.
What the Answer Looks Like
To address this need, we propose a pattern we call Medallion Plus. It extends the standard three-layer model with a fourth layer—Platinum—that sits outside the trust boundary of the originating medallion and can be consumed by audiences who can’t be given direct access to the group’s Gold data.
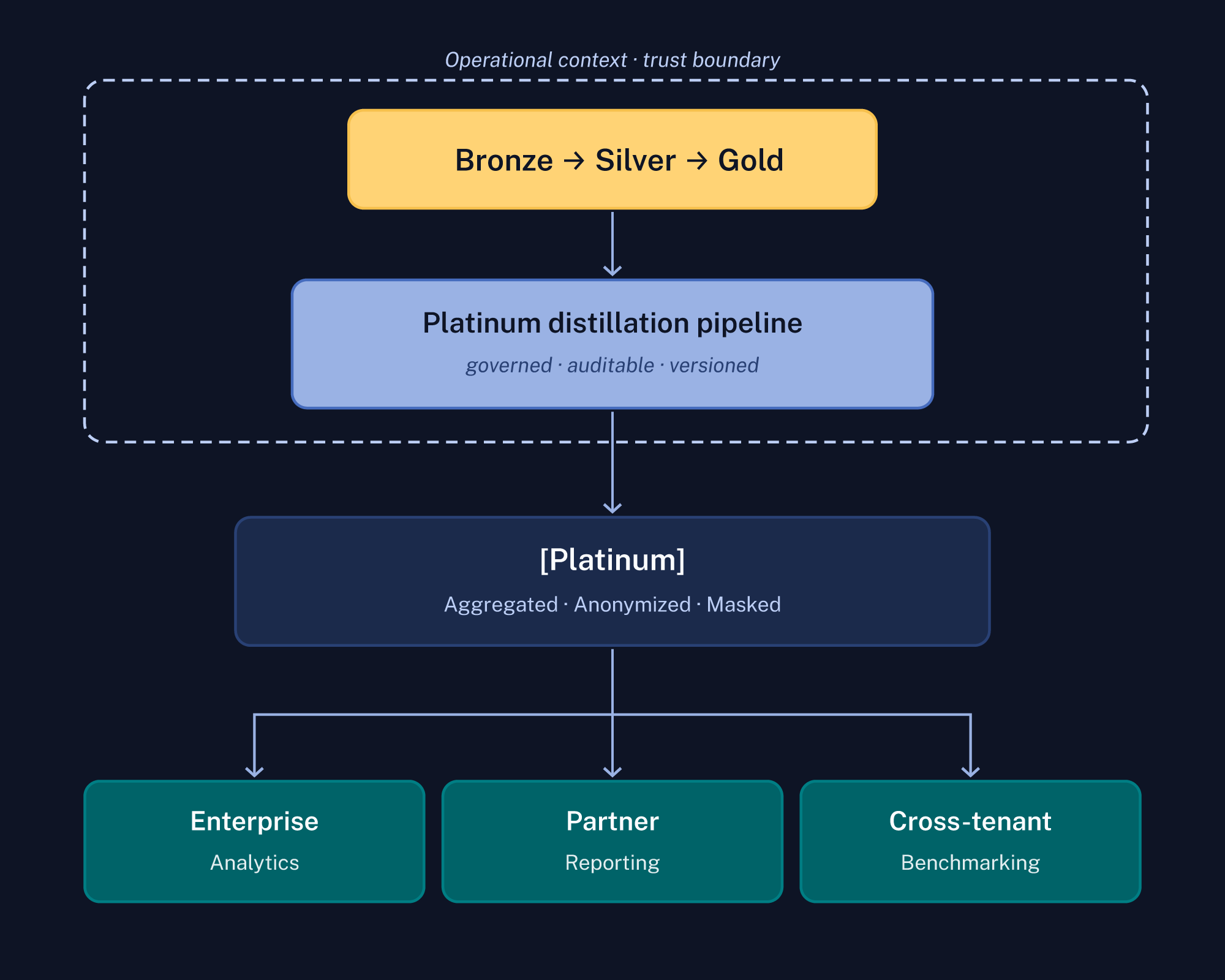
The key word in that diagram is governed. Platinum isn’t a filtered view of Gold; it’s a structurally transformed output produced by a dedicated distillation pipeline before data crosses the boundary.
That distinction matters more than it might seem.
Why Access Control Isn’t Enough
A common reaction to this pattern is: “Can’t you just apply column-level security and call it done?”
Access control is necessary, but it isn’t sufficient for the cross-boundary sharing scenario.
Access controls are a necessary part of the picture, but they operate at the wrong layer for this problem. They govern who can query data — they don’t change what the data is. In practice, leaning on fine-grained controls (column policies, row filters, exception roles) increases governance and maintenance overhead: someone has to design the policy model, keep it in sync with schema changes, audit it continuously, and unwind the inevitable edge cases and break-glass access requests.
Compliance frameworks like GDPR, HIPAA, and others impose data minimization obligations that go beyond access. Consumers may only be able to query against what they need for a stated purpose, not the full dataset with certain columns restricted. A Platinum layer enforced by pipeline architecture addresses that directly — the sensitive data isn’t restricted, it simply isn’t there.
Furthermore, in some scenarios, the option to inject and manage the controls isn’t available. For example, in a cross-organization context, you may be publishing the data to a central repository that you don’t or can’t control access controls to enforce reduced visibility.
The distinction we’d draw: access controls govern who can see the data. The Platinum distillation pipeline governs what the data is allowed to be when it leaves the boundary. Those are fundamentally different concerns and require fundamentally different approaches.
What the Distillation Pipeline Actually Does
There are a handful of relevant transformation categories that can be applied:
Aggregation is the most fundamental. Individual records get replaced by statistical summaries (counts, averages, percentiles) at a grain level that can’t be reversed back to individual subjects. The aggregation thresholds (minimum group sizes, suppression rules for small cells) must be defined by data stewards and enforced in the pipeline, not left to discretion.
Masking and pseudonymization handle direct identifiers. The pipeline owns this step — it can’t be delegated to downstream consumers or satisfied by a dynamic masking layer sitting on top of Gold, because those mechanisms are still reversible by privileged users.
Temporal and spatial generalization is one that gets overlooked. In IoT, logistics, and life sciences contexts, fine-grained timestamps and coordinates are often more sensitive than the primary payload. Exact timestamps become day or week buckets. Precise coordinates become regional aggregations.
Schema projection exposes only the attributes that are necessary for the cross-context use case. Sensitive or irrelevant columns aren’t filtered at query time; they’re structurally absent from the output dataset. Least privilege is enforced at the data model level, not the query layer.
Metadata tagging at distillation time has a specific advantage. There’s a temptation to try to tag sensitive data at ingestion and carry that metadata all the way through Bronze, Silver, and Gold. In practice, that’s difficult to maintain and often gets inconsistently applied by the time you reach Gold. A better approach is to apply sensitivity and context metadata at the distillation step—when you know what the data is being used for and who’s receiving it. The distillation pipeline is the right place to stamp records with data product context, intended consumer, sensitivity classification, and lineage, because that’s the point at which those things become meaningful.
While discussing the operational system with some higher-level architects as part of the earlier referenced project, this was a topic of conversation. One architect pointed out that in their enterprise data system, they use tagging and eventual ABAC to provide similar control. We explained that this was an operational platform, and the data as it exists in the system wouldn’t and couldn’t be shared as is even with tags. The compromise was to explore tagging the data as part of its transformation from the operational platform to the enterprise platform. Their enterprise data platform in this case is the Platinum layer in the context of the operational platform being built.
The Implementation Details That Matter
In typical lakehouse platforms—Databricks, Azure Synapse, or Fabric—this maps naturally. The traditional medallion stack processing lives in a workspace or set of workspaces, and the lake is co-located in a data lake, with the appropriate governance boundaries applied between layers. The Platinum distillation pipeline is either scheduled or runs as stream processing, with read access to the Gold layer and write access to Platinum. Platinum data products land in a separate data lake with its own catalog.
The separation has to be physical, not just logical. The distillation pipeline is the only path by which data crosses the trust boundary.
Also consider refreshing or providing windows over Gold at a lower frequency than Gold for the Platinum datasets. This isn’t just a convention—temporal decoupling adds a practical privacy layer. Point-in-time membership attacks (inferring whether a specific individual was in a dataset at a specific time, for example) are harder to execute against a dataset that doesn’t aggregate over the data at a frequency close to Gold.
Where This Pattern Applies
Multi-tenant SaaS platforms are a clear case. Each tenant’s Gold layer is legitimately isolated. Cross-tenant analytics — benchmarking, aggregate market insights — require a derived layer that probably can’t reconstruct individual tenant records.
Life sciences is another candidate context. The pattern is relevant: run-level outcomes and target class statistics can be shared; compound structures and proprietary assay parameters cannot. There are consortia currently working through sharing this type of data between different companies and organizations, and the approach taken is often one that lines up well with the medallion plus pattern.
Government and regulated enterprise contexts follow the same logic. The organizational driver varies—HIPAA, CUI handling requirements, contractual data segregation—but the architectural response can be the same.
Platinum Might Just Be Another Medallion
Platinum doesn’t have to be a single flat output. Depending on the complexity of what you’re sharing and how many consumer tiers you’re serving, Platinum could itself be another Bronze/Silver/Gold stack—just operating at a higher level of abstraction and a wider trust boundary.
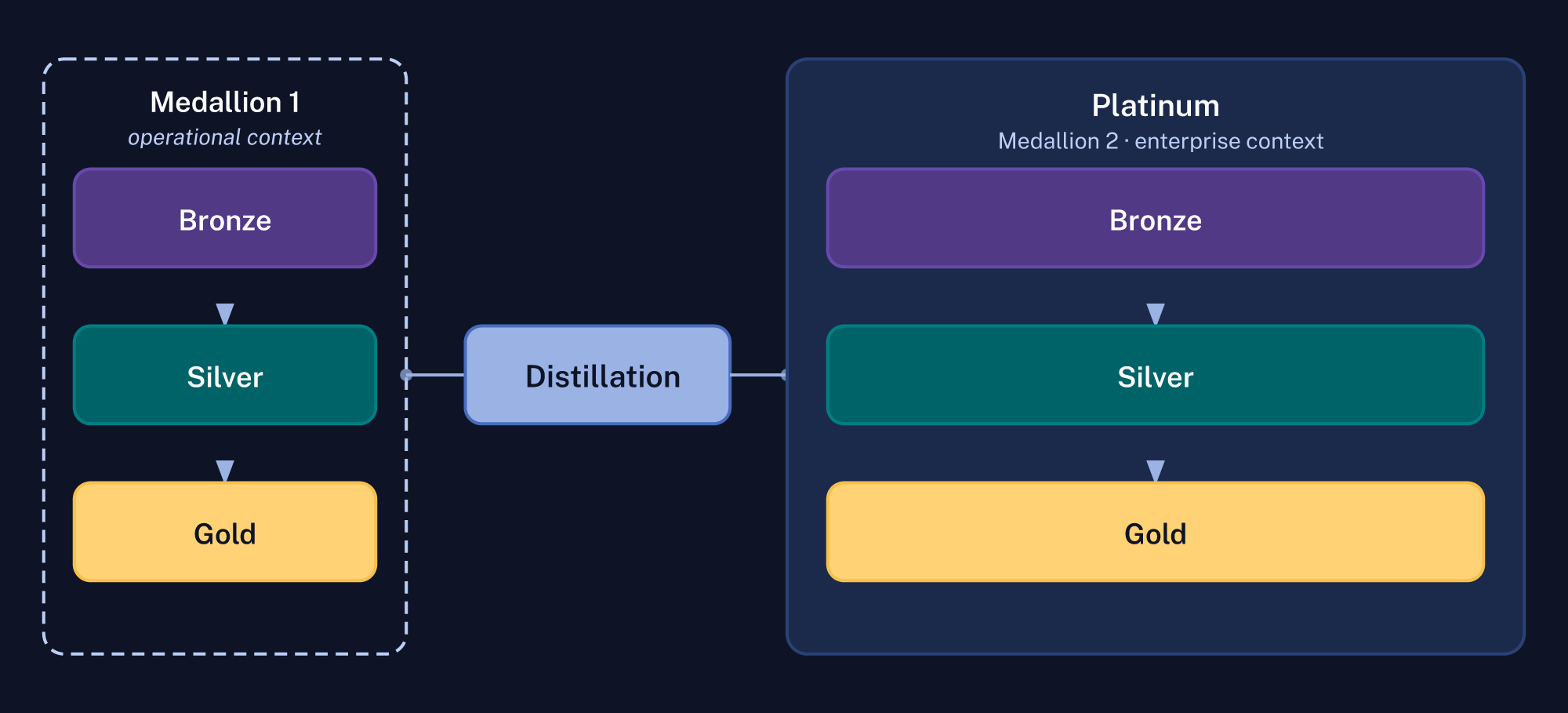
The distillation pipeline produces a new Bronze product for that second stack: raw anonymized extracts, minimally processed. Those get conformed and enriched into a new Silver layer. Publishable data products (the things partners and external consumers actually query) live in the new Gold.
This framing has a useful implication. The medallion architecture isn’t a fixed hierarchy with Gold as the ceiling. It’s a repeating pattern tied to trust boundaries. Each boundary has its own medallion. The distillation step is what connects them. If a second stack eventually needs to feed an even broader audience at yet another level of aggregation, you just apply the pattern again.
How Platinum Extends the Pattern
The standard medallion is a great pattern for organizing transformation within a trust boundary. It doesn’t give you a mechanism for extracting value from sensitive data across one, at least not directly. Medallion Plus fills that gap by adding the concept of a Platinum layer, enabling the safe, explicit sharing of your Gold data to the next level of audience.
✨AI Post Recap
The medallion architecture organizes data transformation well — but it stops at the trust boundary. A Platinum layer, produced by a distillation pipeline, transforms Gold data through aggregation, masking, and schema projection before it crosses that boundary. Sensitive data isn’t restricted on the other side — it’s structurally absent.
What is a Platinum layer in data architecture? A Platinum layer is a transformed output of Gold data, produced by a dedicated pipeline before data crosses a trust boundary. Unlike a filtered view of Gold, it’s structurally different — sensitive fields aren’t restricted, they’re absent from the output entirely.
Why isn’t access control enough for cross-boundary data sharing? Access controls govern who can see data — they don’t change what the data is. Compliance frameworks like HIPAA and GDPR impose data minimization requirements that access controls can’t satisfy on their own.
What does a data distillation pipeline actually do? A distillation pipeline applies transformations — aggregation, masking, temporal generalization, schema projection — before data leaves the trust boundary. The result is a dataset where sensitive information was never included, not one where it’s being hidden.