

We’ve discussed several applications of machine learning before. We teach a machine a concept from stored data so that it can:
- Identify problems with engines from telemetry data
- Identify digits from handwriting
- Identify sticky notes on a board
- Identify the winning team in DotA from team compositions
The common thrust is that, using supervised learning, we’re teaching a machine some concept from recorded data so that we can identify the same concept in data we haven’t seen before. If you look up tutorials on machine learning, you’ll see a similar theme:
- Machine Learning in Python Step by Step
- Kaggle’s Intro to Machine Learning
- Beginners Guide to Machine Learning With Python
Seeing all of these examples, one could extrapolate and assume that machine learning is only good for identifying things. That isn’t true! Machine learning can learn many things, including how to act in a given situation.
Learning to Act
Imagine for a moment that you wanted to teach a computer how to play a game. “Why would you want to automate game playing?”, I hear you cry. Well, perhaps:
- You’re a developer looking to play test your game using algorithms
- You’re a research scientist looking for a domain that will capture public interest
If you’ve played a lot of games, you might start by trying to encode the knowledge you have about a particular game directly:
- When buying properties, prefer railroads to utilities
- When capturing a piece, queens are worth more than bishops or pawns
- Never hit above 17
- And so on
These rule based systems have proven effective in several games (and other situations!). However, they can be prohibitively expensive to produce. It turns out, experts are expensive and video games have many states. Here is where machine learning comes in.
Reinforcement Learning
Just like before, we’re going to try and learn what the expert knows from gobs and gobs of data. You might think we’re going to try and learn what action to take in a state. We are, but not directly. Instead, we’re going to learn how good each action is in a state, and then use that information to select the best action for each state.
Before we discuss a common example domain for reinforcement learning, let’s introduce some common terminology:
Some Terminology
- Agent – A representation of the AI in the environment
- State – some configuration of the world
- Initial State – The state where the agent enters the world
- for example, the start of the game, or the start of a level
- Terminal State – Something that ends the agent’s ability to act in the environment
- for example, winning or losing
- Initial State – The state where the agent enters the world
- Environment – All possible states for the system
- Action – something that the agent is allowed to do
- Episode – A sequence of states and actions leading from an initial state to a terminal state
- Policy – A mapping of states to actions. The policy tells the agent how to behave in a given state.
The Cart and Pole Domain
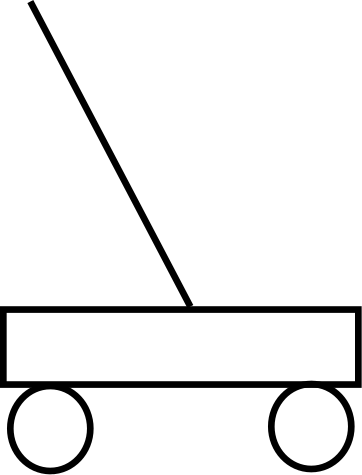
Imagine for a moment that we’re playing the very simple game above. We have a cart, with a pole on top of it. The cart can move left or right, but only so far in each direction. The goal of the game is to keep the pole aloft as long as possible. The game ends whenever the pole falls.
This problem is an ideal case for reinforcement learning. That’s because:
- There are a fixed number of actions: left, right, and do nothing*
- The game has an ending*
- The game has a finite number of states*
- It’s easy to build a simulator for training
How Learning Works
There are many algorithms for solving reinforcement learning problems. In broad strokes, they work like this:
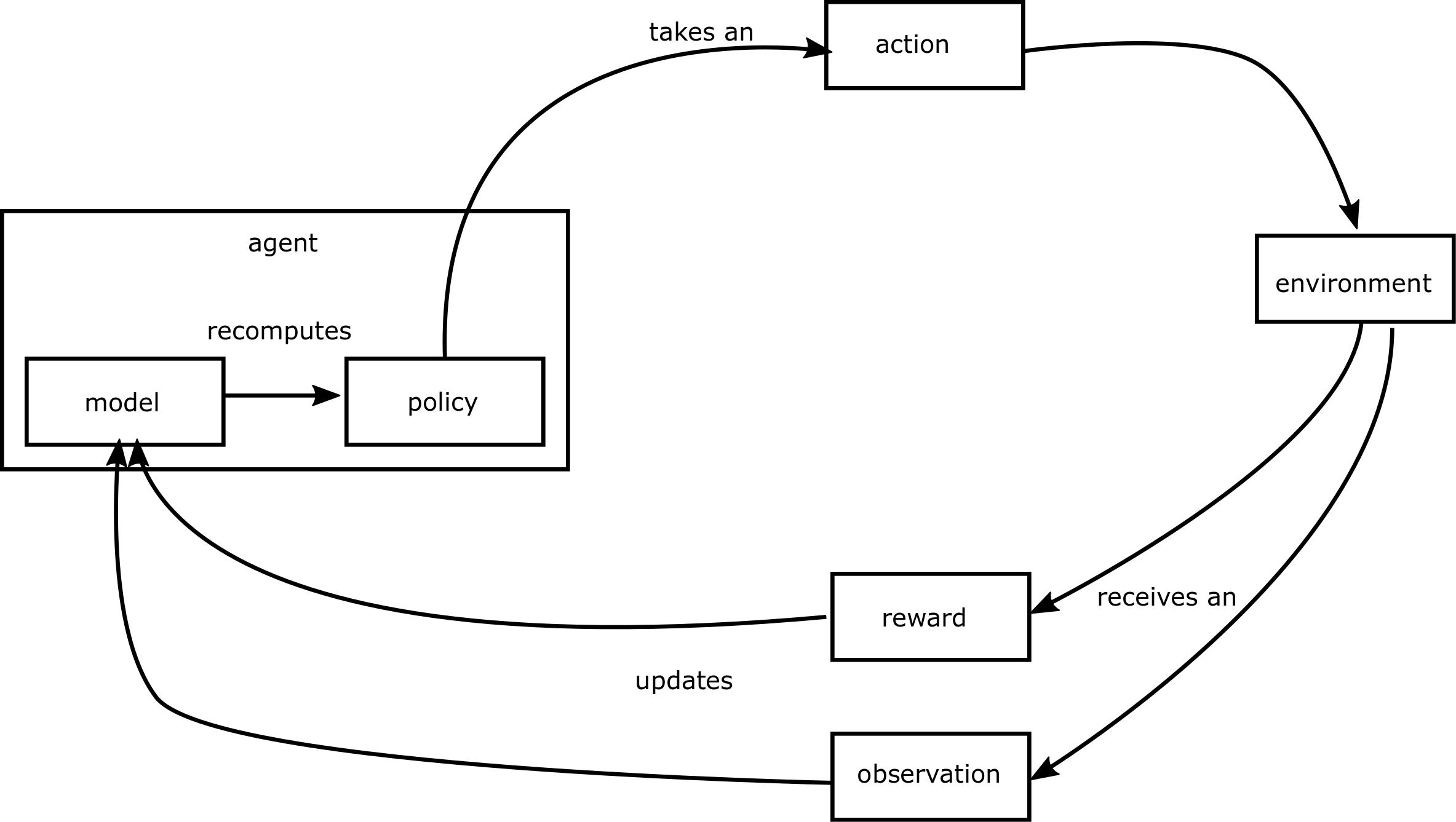
- Put the agent in the environment at the initial state
- Let the agent act in the environment to according to its policy
- Evaluate the action taken based on the reward and observation received
- Use the updated information to improve the policy
- Continue acting until the episode is over
- The environment will tell us when we’re done
- Go back to the top and repeat this a whole bunch
The general idea is that if we let an agent perform over and over again in an environment, and give it feedback on that performance, it can eventually learn to perform well. Reinforcement learning algorithms differ in a number of ways, including:
- Whether or not they explicitly model the domain
- When they consume feedback
- When they update their policies
- How they update their policies
Uses of Reinforcement Learning
Reinforcement learning produces a policy for how to act in any given situation in the environment. This has the obvious application of letting us control an agent to automate a task. Here are some examples of tasks that reinforcement learning has been used to automate:
- Traffic Lights and Compute Cluster Load Balancing
- Smart Grids and Finance
- DRAM control
- Diabetes Blood Glucose Control
- Personalized Medication Dosing
There are several other ways we can make use of the policy:
- Identify abnormal behavior, such as:
- mistakes
- doing actions out of order
- unexpected goals when using the system
- Suggest next actions when performing a task
- Compare learned behavior to expert behavior in order to
- Improve our domain model
- Identify gaps in expert knowledge
Note how the above examples all make use of the policy without ever intending to automate anything. Reinforcement learning generates a description of a behavior. It’s natural to consume that to try and automate a task. However, it’s also possible to use the policy to try and understand a task, or an individual’s internal state. These orthogonal approaches have exciting applications, including caring for individuals with Alzheimer’s disease.
Summary
Reinforcement learning is a sub-discipline of machine learning. It helps us build AIs that know how to act in a given situation. It’s most applicable when:
- The environment is finite
- There are a small number of actions we can take
- Episodes are finite
- A simulator exists or can be cheaply built
Knowing how to act in a given situation can help us automate agents to work in known environments. However, we can also use those policies to perform a number of other important tasks, such as identifying abnormal behavior.
Wait, What Were Those Asterisks For?
It’s not obvious that the correct representation of the cart and pole problem has only three actions. We might want to model actions as a direction and an acceleration, for example. Similarly, it’s easy to imagine a policy which balances the stick forever in which the game has no ending. Finally, you may wonder if the state space for the game is really finite, considering that we’re representing the angle of the pole to the cart which is a continuous value.
First, those are all correct and astute observations. Each of the above issues needs addressed when applying reinforcement learning. We can address those problems in how we model the problem we’re trying to solve, by applying advanced reinforcement learning techniques that can deal with more complicated domains, or both. The thing is, none of those complicated wrinkles really change the general thrust of what reinforcement learning does to solve a problem. Here, we were trying to convey reinforcement learning at a very high level. In the future, we’ll delve into complications like these and techniques for addressing them.
Unlock the Power of AI Engineering
From optimizing manufacturing materials to analyzing and predicting equipment maintenance schedules, see how we’re applying custom AI software solutions.