

Natural Language Processing (NLP) is a method of computer interaction at the intersection of human language, computer science, and machine learning. It can be thought of as a way of helping computers interpret text and speech as a human would, including understanding the subject, context, or both. This blog post will focus on getting started with a basic form of NLP, called sentiment analysis. Additionally, Python was chosen as the language for the example, due to its ease of use and helpful modules.
Sentiment Analysis
One of the more interesting things that can be done with NLP is sentiment analysis. This process identifies the “feeling” expressed in text. Words like “useless”, “bad”, and “hate” convey a negative sentiment, whereas “loved”, “enjoy”, and “yes” have a positive connotation. Other words, such as “ok” and “fine” are more neutral.
In addition to the polarity (positive, neutral, or negative), each word can also convey a magnitude of the sentiment being expressed. If you love something, chances are that you feel more positively about it than something you only like.
Sentiment analysis has a wide range of areas it can be applied. It can be used in understanding the mood of a social media post, predicting optimism in the stock market, or discerning which features of your product are the least popular.
Twitter Sentiment
As mentioned above, gleaning inclination from social media posts is a popular application for sentiment analysis. The example that follows demonstrates how to gather messages from Twitter, and analyze the sentiment therein.
A Note on Python Versions
This post makes the assumption that you are using Python 3. After all, at the time of writing, Python 2 is nearing end of support.
Installing Modules
For this example, we will be using Natural Language Toolkit (NLTK) and Tweepy.
The Natural Language Toolkit (NLTK) is a mature Python library that has many excellent utilities that abstract Natural Language Processing processes.
Tweepy is an easy-to-use Twitter client for Python, and it will allow us to gather tweets to analyze. In order to use Tweepy, you will need a Twitter developer account.
The following command will install both modules:
pip3 install nltk tweepy
NLTK contains a sentiment analyzer called VADER, which stands for Valence Aware Dictionary and sEntiment Reasoner. It was originally developed to analyze text from social media, and uses rules based reasoning, rather than following a machine learning model.
Rules based sentiment analysis relies on a mapping of positive, neutral, and negative weights to English words called a lexicon. The sentiment analyzer uses the words and weights in the lexicon to calculate a polarity score for a string of text. Before we can use the VADER sentiment analyzer, that lexicon must be downloaded.
To initialize VADER, start an interactive Python session in your terminal by running python3. Next, import the toolkit with import nltk. Finally, download the lexicon by entering nltk.download('vader_lexicon').

Once those commands are run, you should see an ‘OK’ message confirming the download. To close out of the Python session, type ctrl + D.
Ensure that the Tweepy and NLTK VADER modules are imported to our script:
import tweepyfrom nltk.sentiment.vader import SentimentIntensityAnalyzerNext, we set up our Twitter client. Tweepy requires the consumer key and secret that each developer app has, as well as a generated access token and secret. Replace these values in the script with your own:
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)api = tweepy.API(auth)In order to process the tweets we will request from the API, we need to instantiate a sentiment analyzer. This class does all the heavy lifting computing the sentiment scores using the VADER lexicon and the text.
analyzer = SentimentIntensityAnalyzer()Now, it’s time to fetch some tweets! The Tweepy client allows public tweets to be retrieved with a key word or query using the search method. For our first filter, let’s choose something that most people might regard positively: cake. We will request the first 1000 tweets that mention “cake,” and filter out tweets that are not in English, just for ease of example.
topic = "Cake"tweets = api.search(topic, count=1000, lang="en")Now we can loop through the tweets, and have the analyzer compute the sentiment scores for each one:
for tweet in tweets: print(f"\n{tweet.text}") # Calculate the positive, negative, and neutral sentiment scores # Also produces a compound value representing overall feeling scores = analyzer.polarity_scores(tweet.text) for val in sorted(scores): print(f"{val}: {scores[val]} ", end='')Here’s one of the resulting tweets, as well as the score that VADER sentiment analyzer gave it based on the language used:
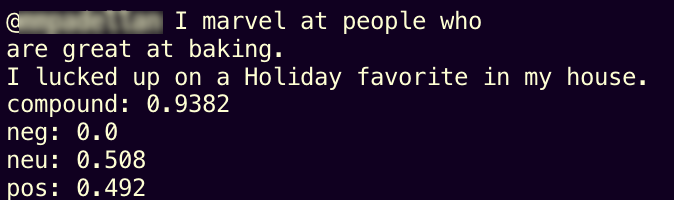
If we change our loop slightly, we can calculate the average sentiment (based on the compound sentiment value for each tweet) for a topic:
compound_scores = []for tweet in tweets: scores = analyzer.polarity_scores(tweet.text) compound_scores.append(scores["compound"])avg_sentiment = sum(compound_scores)/len(compound_scores)print(f"\nAverage Sentiment of {topic}: {avg_sentiment}\n")Using “cake” as a topic again, we can see the average compound sentiment for 1000 tweets is relatively positive:

On the other hand, if we change the topic to “cold,” a different reaction emerges:

The response to “cold” is negative, but with a lesser magnitude than the positive sentiment for “cake.”
Other Applications
Sentiment analysis is not the only application for NLP and Python. Much like image classification with machine learning, groups of text can be classified as well. Text classification can help understand the subject of a sentence, paragraph, or even web page.
Natural language processing is also helpful when trying to make text-based interfaces easier to use. For example, a Slack bot that can correctly interpret the context of a request would be able to direct a user to the right resources more quickly.
Unlock the Power of AI Engineering
From optimizing manufacturing materials to analyzing and predicting equipment maintenance schedules, see how we’re applying custom AI software solutions.