void Function()
{
try
{
RunOtherFunction();
}
catch
{
Log.Error( "Problem" );
}
}
void RunOtherFunction()
{
if ( a_okay() )
{
OtherFunction();
}
else
{
throw new Exception( "Error" );
}
}Exceptions are a thing that we tend to use for signaling error conditions such that the error will be dealt with in some other location besides the current code location. There’s a lot of philosophy that goes into when and how you use exceptions, but I’m going to ignore all of that. Here we’re less interested in how or why someone uses an exception and more concerned with the effect that the exception will have on understanding and working with a code base.
Exceptions are dynamic code communication channels
So what are exceptions in a mechanical sense? An exception is a way to communicate with some arbitrary function above your current function in the call stack. Because there is more than one possible way for any given function to be called, it generally cannot be statically known which function will be the function that catches a thrown exception. And knowing which function catches your exception isn’t the point. The point is that you have a situation that you do not want to handle in your current function and you want some other function to deal with it.
Exceptions form restrictive sub trees
There’s probably a couple of ways that this could make a code base difficult to deal with. But we’re only going to cover one for the time being.
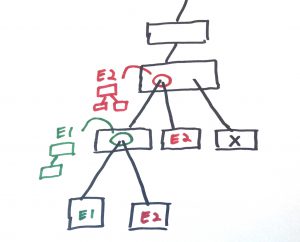
In the above diagram we see a couple of locations where different exceptions will make sense to be thrown from. The red circle represents a catch statement that handles the E2 exception and the green circle represents a catch statement that handles the E1 exception. There are a few places where we can throw an E2 exception and there are less places where we can throw an E1 exception. The X function shows us a location where we can throw no exceptions.
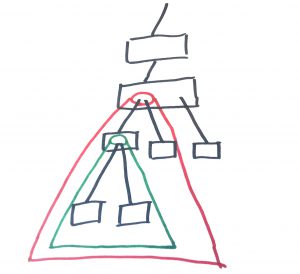
What this means is that we end up with a sub tree where some exceptions are allowable. This is problematic because it means that certain code changes or refactors will result in discontinuous behavior. Modifying the structure of the code base just a little will result in a large difference when the program is run.
void MajorFunction()
{
MinorFunction1();
MinorFunction2();
}
void MinorFunction1()
{
try
{
HelperFunctionAlpha();
HelperFunctionBeta();
}
catch
{
// Handle exceptions
}
}
void MinorFunction2()
{
HelperFunctionBeta();
}
void HelperFunctionAlpha()
{
DefaultLog();
}
void HelperFunctionBeta()
{
// No exceptions here
}
void DefaultLog()
{
if ( !logger_active )
{
throw new Exception( "no logger" );
}
}Everything in this program should run just fine. But what if someone makes the following change:
void HelperFunctionBeta()
{
DefaultLog();
}This code change can be problematic. The DefaultLog method throws an exception, but we do not handle any exceptions in the HelperFunctionBeta method or in any higher method. There are now more details that you have to consider when trying to understand the program. Additionally, it might not be obvious that DefaultLog throws an exception at all. It may be implemented in another file or it may call another method that throws the exception. The exception may only be thrown in rare situations such that it will not be noticed until after the code has already been deployed. Finally, the exception might be caught at a much higher level in the call stack. It might not be obvious at all who is supposed to be catching exceptions and the software engineer that makes this change may not know that the new configuration will result in an uncaught exception.
