

Before we can measure how difficult a code base is for software engineers to work with, we have to also have a method to measure how difficult problems are for people to work with. This gets a little bit difficult because the idea of a “problem” can get very philosophical and we want something a more concrete. For example, imagine a fence around a house. A thief will see the fence as a problem that keeps him from robbing the house, but the home owner will see the fence as a solution to keep his house safe from the thief. Perspective shouldn’t change whether or not a problem is a problem with respect to engineering work, so we need a very specific meaning of the word “problem” in order to keep things in a workable state.
The definition of “problem” that we’re going to be working with is: Aspects of a situation that makes understanding its behavior difficult. There’s other ways to think of problems, but this way is useful for our purposes.
Why do we need to understand how problems are hard? There are a couple of reasons.
- Not all problems are equally easy to resolve. And if you’re trying to resolve the problem with a software solution, you need to understand when the problem is difficult and when it is easy. A difficult problem might merit difficult to deal with code. While an easy problem should expect easy to deal with code. This is sometimes talked about as accidental complexity and essential complexity.
- People can train themselves to be good and solving problems in such a way where it is not obvious how much work they’re actually doing. Sometimes problems are hard just because they are unfamiliar, but once you understand what’s going on everything becomes simple. Being able to differentiate between something that only looks difficult and something that genuinely is difficult can be very useful.
- Some of the later techniques that I want to discuss need to have a way to analyze them. The problem analysis techniques that I’m going to go over here are going to be reused later.
- Libraries, APIs, interfaces, and really any code that’s intended to be used in a black box way can be analyzed this way. When you’re not allowed to look at the source code (maybe for bad reasons or maybe for good reasons), how do you objectively say that the interface that is available is good or bad. These techniques should give a way to indicate why an API is good or why it is bad for software engineers using it.
So how do we measure the type of problem that I’m talking about? Well, I have several aspects that have an impact on how difficult a problem will be for a software engineer. I’m going to talk about them over the course of several blog posts. Providing diagrams and examples to try and get the point across. First, let’s do a primer to show the kind of diagram that I’m going to be using for this part of the blog series.
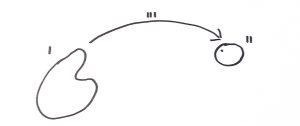
We’ll go over each part of this diagram, however the idea is to model the problem under analysis as the possible states of the system, the possible states of the system after some action or transition, and the aspects of both possible states as well as the transition.
The first blob labeled I is the set of possible valid inputs for the transition labeled III. The second blob II is the possible set of outputs from the transition III. If your system is a library, then III is going to be a function call. I is going to be the set of inputs that make sense to send into the function III. And II is going to be all the possible outputs you can get from III when you call it.
The inputs that I represent and the outputs that II represent don’t have to just be function parameters and return values. The library function might change a global variable, write to a database, or throw an exception. All these things should be included in the blobs I and II.
What constitutes a “valid input” is going to depend on your application. Any input that provokes a nonsense output will almost definitely be an invalid input. But you do have to understand the nature of your transition III in order to know when the output is nonsense. Some inputs will yield exceptions and that might constitute an invalid input, but again context is vital. A NullReferenceException is probably indicative of invalid input, and a FileDoesNotExistException is a plausible result from a valid input, probably. Again, context is important here. The idea is valid inputs are inputs that allow the system as a whole to continue functioning in a healthy state. This will be important later when we start to get into the aspects that can cause a problem to be difficult for people to address.
Another example of a problem that you can analyze with this sort of diagram is public speaking. In public speaking the blob I would represent what your situation is right now. Have you been introduced, is the audience paying attention, is there a heckler causing a disturbance, etc. The transition III represents something you say, some body language you’re using to convey an idea, a slide on a presentation, or a diagram you’re drawing on a white board. Finally, the blob II represents the situation you’re in after you perform the action from III. Does the audience understand your point, are you getting applause, are you getting questions, are people falling asleep. Invalid inputs from the I blob are going to represent situations where you can no longer continue with your speech. In other words, there is no action you can take as a speaker for the event to continue in a healthy way. So a fire has broken out, the audience has turned unruly and is moving to attack you, a complete power failure has occurred and you can’t speak loud enough to reach the entire room.
The next blog entry is going to focus on the nature of the blob I and how that can impact the difficulty of working with a problem.