

As an industry, we’ve dedicated a lot of effort into getting better feedback faster. We’ve embraced small batches of work (iterations) that we can deliver and receive feedback upon faster. We perform user studies and observe people interacting with the software we create. We use clickable wireframes or paper prototypes to evaluate the effectiveness of interface designs before spending the time to actually create them in code. Each of these changes allow us to validate our assumptions or course correct sooner (before building more of the wrong thing).
Automated builds are one (of many) tools that can provide feedback to a development team. An automated build can tell whether a change has introduced a compile error, whether it has broken existing behavior (codified in automated tests), or whether how a change impacts various measures of quality and performance. As with the feedback mechanisms the industry has embraced at a macro level, the feedback provide by automated builds is more useful if it can be provided quickly.
Parts of a build
On a typical project, there are several processes that could occur during an automated build:
- Compiling the software
- Running automated unit tests
- Running automated system tests
- Gathering code coverage metrics
- Evaluating conformance to style guides
- Static code analysis
- Automatic deployment to a test/staging server (or even to production)
While these could all be done as part of a serial, monolithic processes, recognizing that there are many different steps affords the ability to restructure builds to provide faster feedback.
Splitting apart builds
At a high-level, build pipelining is the practice of have multiple builds that are triggered in a sequence. Often this will also involve running some of the build steps in parallel.
Consider a monolithic build that involves several of these steps:
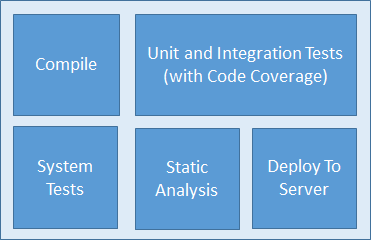
In a build pipeline setup, the build might look something more like the following:
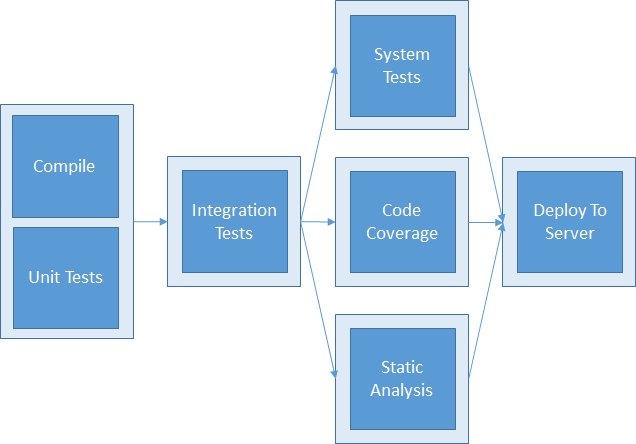
Faster feedback
Each of the sub-processes that exist during a typical software build provide different types of feedback. While feedback from all of the steps is useful, a development team can respond to negative feedback (compile errors, failing unit tests, etc.) without needing the feedback from all of the steps in the process. Proving a team feedback through smaller, faster, more targeted builds allows a team to respond to a issue nearer to when the change is made (and before too much time is spent making subsequent changes based upon code that has introduced an issue).
For example, the first build in a pipeline might compile the application and run unit tests. At that point, we’ve ruled out any basic, fundamental errors quickly before spending the time to perform the costlier build operations (such as system tests or static analysis).
As a side benefit, there is often a chance to reduce total end-to-end completion of all of the sub-processes. While some of the steps in a build process need to proceed serially, there are many steps that could be done in parallel. For instance, running system tests and performing static code analysis could happen simultaneously. Since those two steps often take some time, running them in parallel can shorten the amount of time between when a change is made and the last piece of build feedback is available.
Example setup using Jenkins
The basic methodology of splitting builds into smaller steps that can be run in sequence (and parallel) works with most automated build systems. As an example, I’ll use to Jenkins as a tool to show one possible way to configure such builds. There are several ways to chain builds together in Jenkins. The one I’ll focus on for this example is the “Build other projects” option. The basic mechanics of that option are to kick of one or more other builds when an build completes.
Let’s start with the original build configuration, which performs the build activities in sequence as part of a single build.
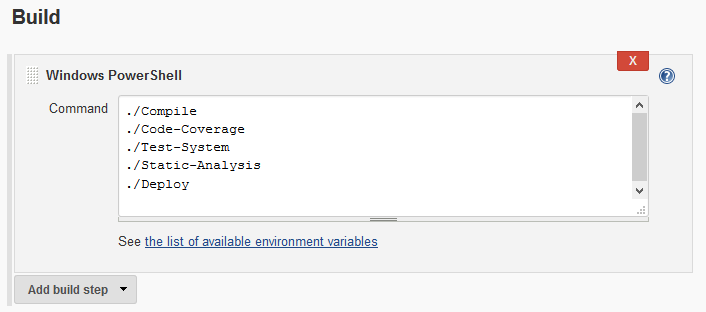
Before breaking this build apart, I’d further subdivide some of the build scripts to split apart running unit vs. integration tests and running tests with and without code coverage (which can introduce a substantial time delay in the execution of tests). At that point, each individual build operation can be assigned to its own build in a build pipeline.
To set this up in Jenkins, first create multiple builds, one for each step in the pipeline process. In this example, that means separate builds for:
- Compiling and unit tests
- Integration tests
- System tests
- Code coverage
- Static analysis
- Deployment to a test server
The first build in the process is the only build that needs to be triggered via source code changes.
To initiate all of the other builds in the process, add a Post-build Action of “Build other projects” option and specify the next build(s) in the process.
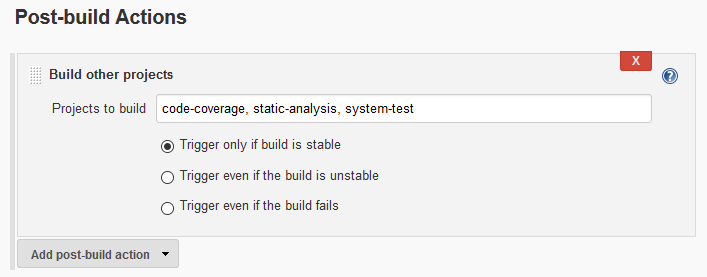
Repeating this process for each of the steps in the overall build process, and leaning on the option to perform some of those steps in parallel, the final build configuration might end up something like this.
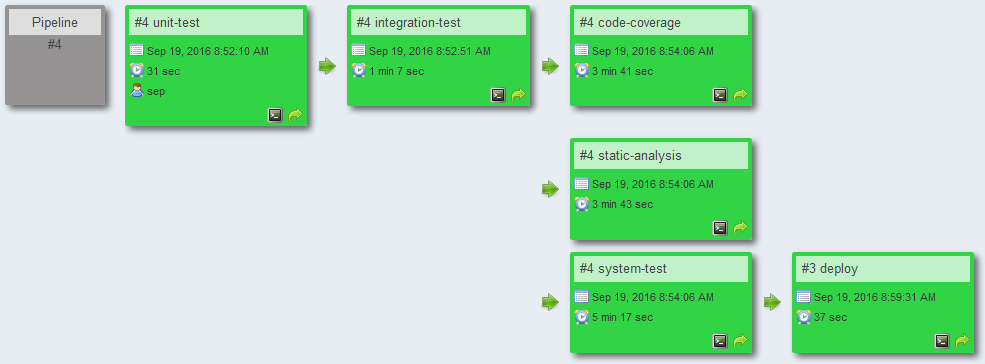
End result
When completed, a pipeline approach provides more granular feedback, more quickly, and with less total time between the start of the first build and the conclusion of all of the build steps (now in separate, chained builds).
Notes
The methodology used in this setup is supported out of the box by Jenkins. I did, however, use one additional plugin (Build Pipeline) to show a visualization of the build pipeline.