

Blog Post Written By: Lisa Lo
Artificial Intelligence (AI) is no longer science fiction; it’s here today, and it’s here to stay. It is in the products you use every day: home automation, digital assistants, and credit card fraud detection, to name a few.
AI will affect all businesses in the near future, and the impact will be significant. The only remaining question is: how do I get started?
There can be a steep learning curve when first using AI. There are three reasons for this:
- Many of our natural assumptions around AI are wrong.
- Expectations around the development process don’t match reality.
- Explainability is rarely considered when developing an AI.
Yet, by carefully considering these ideas, everyone can succeed in using artificial intelligence.
Five Faulty Assumptions
When we first start working with artificial intelligence, it’s easy to make assumptions about how it works. Here are five common, but faulty, assumptions we should avoid.
1. AI has general human capabilities.
We expect an artificial intelligence to be able to do the same things a human can do. Said another way, what’s easy for humans should be easy for a machine. A human can see an object on the ground and pick it up. However, this is a very challenging task for a machine. It must see the object, understand what it’s seeing, determine how the object will react when it is manipulated (will it deform, is it rigid, etc.), and then decide how it’s going to act. You can see this process in action with this video of a towel folding robot. Keep in mind it’s sped up 50x, so the robot takes close to an hour to fold two towels.
Amazon had to deal with this same assumption when building its warehouses. Machines do what they are good at (heavy lifting, transporting shelves around the warehouse quickly); humans do what they are good at (verifying the items brought to them, making in-the-moment decisions). The key is to recognize a machine’s strengths and a human’s strengths to build a system that complements both.
2. AI understands the context in which it’s being used.
An AI only understands the context (inputs) it is given and nothing more. One such example is IBM’s Watson. Watson was specifically built to compete on Jeopardy. However, it wasn’t told the category for each clue, which sometimes caused it to answer wrong. Watson was missing that critical piece of context.
Another example is when a research team built an app to determine whether an image was of a wolf or a dog. While It seemed to work, it was actually detecting snow versus grass. Because most of the input images of wolves were in the snow and of dogs were in a park, it had learned the wrong concept. While humans intuitively know that we want to differentiate the animal in the picture, and not the background, the AI did not since it was not told the context of the problem. In the end it was a snow detector rather than a wolf detector. The solution was to remove the background of every photo; thereby the AI learned what was important (the wolf or the dog).
3. Automation is an all or nothing proposition.
It is natural to think that if we’re automating a process, we need to automate the entire process; otherwise, it’s not worth the time or effort. But that’s not always an efficient use of humans or machines. As we saw in Faulty Assumption #1, supplementing a machine’s capabilities with the human’s abilities is the best of both worlds.
In the medical field where accuracy is essential, it’s been found that a combination of doctors plus AIs have a better rate than either have by themselves:
Our study found that AI detected pixel-level changes in tissue invisible to the human eye, while humans used forms of reasoning not available to AI. The ultimate goal of our work is to augment, not replace, human radiologists.
— Krzysztof Geras, assistant professor in the radiology department at New York University’s Grossman School of Medicine, AI boosts breast cancer detection accuracy
And of course, a cancer diagnosis (or non-diagnosis) is better delivered by a human who can empathize with the patient.
4. AI Systems are unbiased.
AI in their pure mathematical status should be unbiased, but that is untrue. As we saw in Faulty Assumption #2, the wolf detector had biased input data, so it was answering the wrong question.
Another example comes from the UK passport system. The system was set up to recognize specific criteria and approve the passport photo only when all criteria were met. Pretty straightforward, in theory. But the system rejected some acceptable passport photos because of a fault in its input data. Human faces come in all shapes, sizes, and colors and the system simply didn’t have enough examples in its database to correctly identify acceptable passport photos every time.
When humans are involved, it is easy for their biases to be present in the input data they gather. Algorithms themselves do not have bias; however data does. So, if the input data has biases, then the AI will have biases. We must be careful to guard against this by training the AI on data which is representative of everyone who could use the system.
5. AI means intelligence as humans understand it.
We tend to believe the “intelligence” in “artificial intelligence” is the same as in “human intelligence”; that an AI goes through the same thought process as a human to get to the solution. But AI approaches problems differently than humans. It is made up of a pile of algorithms and it follows those to a conclusion. It might be the same conclusion that a human would make, but how it arrived at that conclusion is very different. This distinction can be a great advantage. Computers can be unconstrained from past knowledge and strategy, and therefore really challenge how humans think.
For example, the game of Go is a strategy board game, much more complex than Chess. It has been around for thousands of years and in that time, humans have established strategies for play. Google’s AlphaGo changed the way humans look at the game when it won a match against Lee Sedol, one of the world’s top players, by making a completely unexpected move. AlphaGo never would have made this move if it had stuck to conventional human strategies, but it was unencumbered by the past and came up with a new way of ‘thinking’ about the game.
An iterative and experimental process
Along with the assumptions, it’s important to approach the development of artificial intelligence in an iterative fashion, with an experimental mindset.
First, let’s define two terms:
- Utility is the reason we’re interested in building AI: higher accuracy, less processing time, faster development time, or any of the myriad reasons we have.
- Investment is whatever you spend to achieve a goal: headcount, budget, time, etc.
We have found that development typically follows an S-curve with 3 distinct phases.
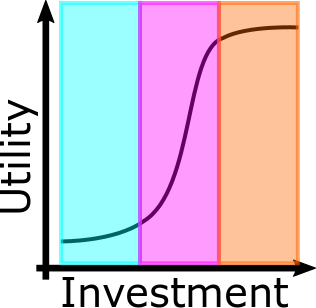
First, the feasibility phase (highlighted in blue). The goal of this phase is to determine if it can be done at all. Can we build Data from Star Trek? No – and we can find that out quickly. If this problem inherently can’t be solved, the curve will remain flat. If it can be done, the S-curve will start to form.
Second, the initial development phase (highlighted in purple). The goal of this phase is to determine if we can afford to build it. If the curve starts to rise sharply, we’re on the right track. This probably involves trying several different techniques and approaches to see what tradeoffs each have on this specific problem (see the next section for more on that).
Lastly, the polish phase (highlighted in orange). The goal of this phase is to determine if it’s ready to release. In this phase, the major development is finished; it’s just finishing those last bits of fine tuning and putting the finishing touches to ensure the product is ready to be used. While seemingly simple, it unfortunately takes a lot of time, leading to the level off of the curve. As a result, it’s up to you to choose when the product is ready for release. There’s no right or wrong answer, rather the question of: is this good enough for my purpose? If so, then it’s ready to go!
Admittedly, there is one more phase after the polish phase that is rarely considered: maintenence. Maintaining the system: knowing when to retrain, when to update the algorithm, what data to keep or throw away, also requires time and effort. Just like in the polish phase, these questions have no right answer. It’ll be your choice when to do further maintence and when it’s enough for your purposes.
Tradeoff: utility versus explainability
There’s one more term to define: explainability. Explainable artificial intelligence is when the AI system produces a solution understandable by a human expert (and ideally even a layperson). Furthermore, how the AI arrived at that solution can be understood. Contrast that with the concept of “black box” AI where even the system’s designers cannot explain why the AI arrived at a specific decision.
Why does explainability matter?
- Understanding why a decision is made helps detect bias earlier, like the passport photo verification system we saw in Faulty Assumption #4. People can evaluate whether there are any issues in the system early on and adjust accordingly.
- Understanding how a decision is made helps with determining accountability. For example, if someone is misdiagnosed in the situation we saw in Faulty Assumptions #3, breast cancer diagnosis, accountability becomes a big question. AI algorithms themselves can’t really be sued, but depending on the situation, related parties can. While explainability doesn’t say in black and white who should be held accountable, it does still help.
- Understanding how decisions are made helps developers fix issues. Consider the case of the wolf detector from Faulty Assumption #2. If the designers knew the system was putting more weight on the background, they would have found the solution of removing the background from photos much quicker.
- Having explainability helps build trust with the people using the AI. If someone knows the reasons an AI arrived at a decision, then they can decide whether they trust those reasons and therefore trust the AI. Without explainability, users have to trust the creators that it works.
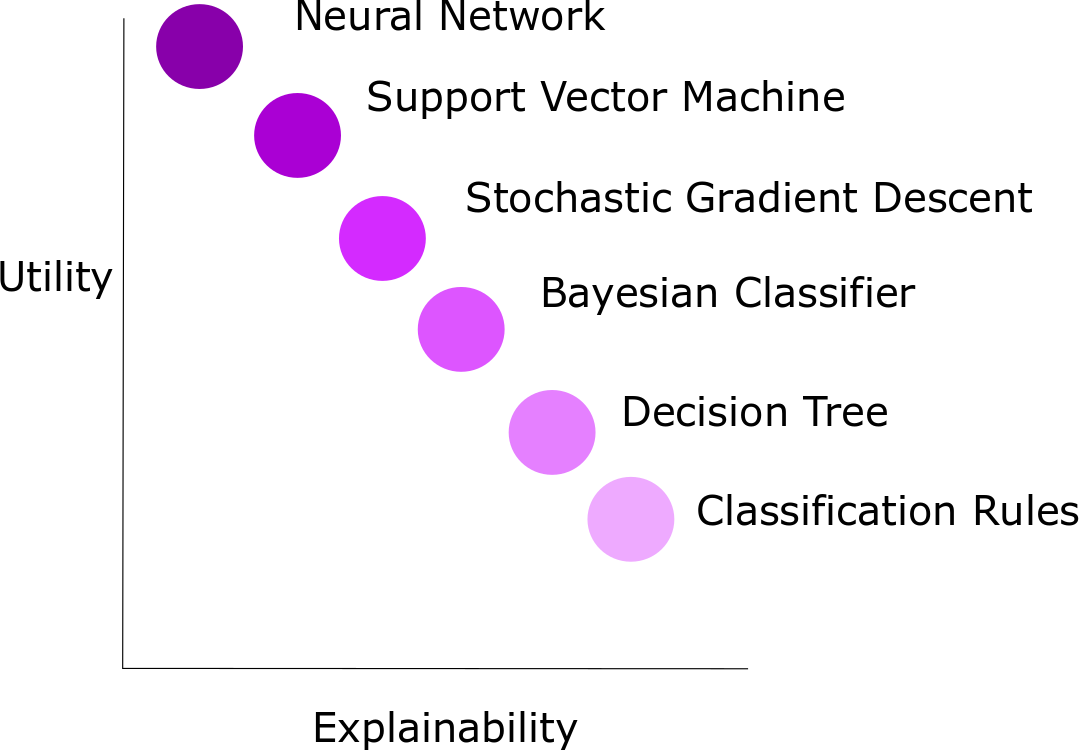
So, what’s the tradeoff? Well, per the picture above, in general the more powerful the AI technique, the less explainable it is. This is not an exhaustive list of AI techniques, nor is this rule universally applicable. But it is consistent enough that we need to be careful of it. There is a lot of ongoing research in this area.
Now, not every AI system needs to be explainable, but that decision must be deliberate. Think of explainability as a non-functional requirement to be explored in the feasibility phase of development.
Conclusion
It may seem like a lot to think about, but in the end there’s only a few core ideas to remember:
- Fix Faulty Assumptions
- AI does not have the same capabilities as humans: AI and humans each have different strengths.
- AI does not understand context: AI needs to be told exactly what it needs.
- Automation is not all or nothing: sometimes the best solution is to use both AI and humans.
- Algorithms can be biased: be careful of what the inputs are.
- AI does not mean intelligence as we understand it: AI has a very different process, following algorithms rather than human thought processes.
- Practice Iterative Development; watch the slope of the S-curve during each phase and understand what it tells you about the problem you’re solving.
- Deliberately Consider Tradeoffs; learn what level of more utility comes at the cost of explainability is necessary for your product and how that impacts which techniques are feasible.
When we accept that we need to take an experimental approach to building AI, that failures will happen, and constantly improve iteratively, success will come with it.
Unlock the Power of AI Engineering
From optimizing manufacturing materials to analyzing and predicting equipment maintenance schedules, see how we’re applying custom AI software solutions.