

Lately, we’ve been fielding a lot of interest in custom Retrieval Augmented Generation (RAG) systems. And honestly, it’s easy to see why. RAG systems are incredibly flexible tools for injecting up-to-date, domain-specific knowledge into AI responses for answering questions, generating content, analyzing internal data, or any other task that’s primarily completed by producing an artifact.
Still, it’s worth asking, “If I can buy a RAG system as a service, why would I ever spend the time, effort, and money to build one?”
To answer that question, let’s take a high-level tour of how RAG systems work, why they’re so powerful, and where customization can meaningfully impact the performance of the overall system.
RAG in Plain English
RAG, short for Retrieval Augmented Generation, is a technique that helps large language models (LLMs) stay grounded in the right context. It’s like giving the model an open-book test: instead of relying only on what it was trained on months ago, the system pulls in relevant, up-to-date material from your own knowledge base. Then it asks the model to generate a response based on that.
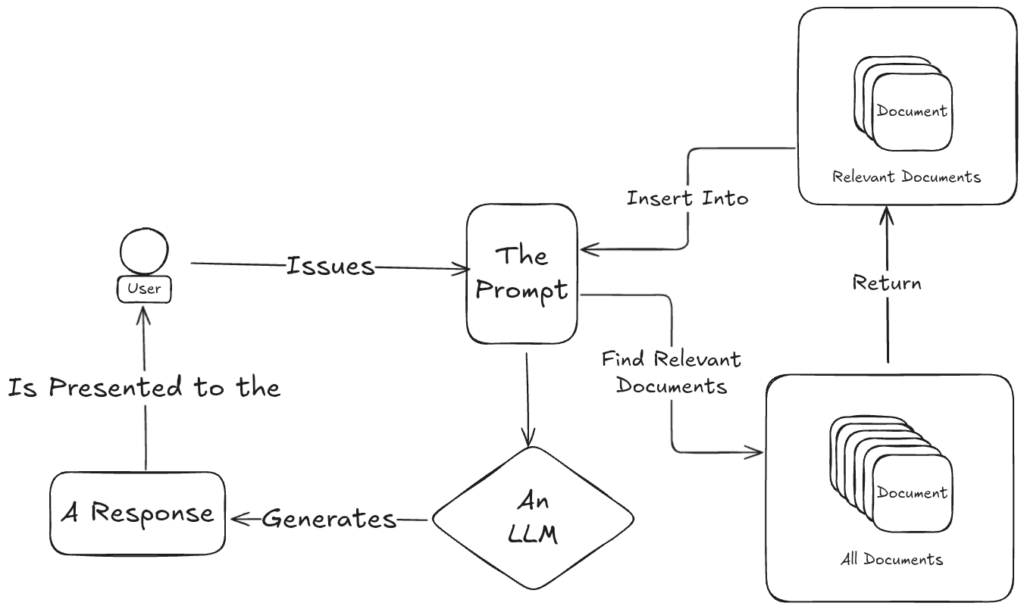
Key Ingredients
To understand how RAG works, let’s define a few terms:
- The Prompt: What the user wants: a question answered, a document summarized, an image described.
- All Documents: Your full corpus, including policies, project docs, Slack transcripts, meeting notes, you name it.
- Relevant Documents: A filtered subset that actually applies to the prompt at hand.
- The LLM: The AI engine doing the generation, taking both prompt and context as input.
- The Response: The model’s response to the user’s prompt given the critical context provided by the documents in the corpus.
The General Flow
Here’s the basic lifecycle of a RAG interaction:
- A user makes a request (“What’s our PTO policy?” or “Summarize last quarter’s compliance changes.”)
- The system searches the document corpus for relevant context.
- It packages the query and those documents into a prompt for the LLM.
- The LLM generates a response.
- The system returns that response to the user.
Simple on paper. But like most systems, the devil is in the details.
What Goes Into a RAG Prompt?
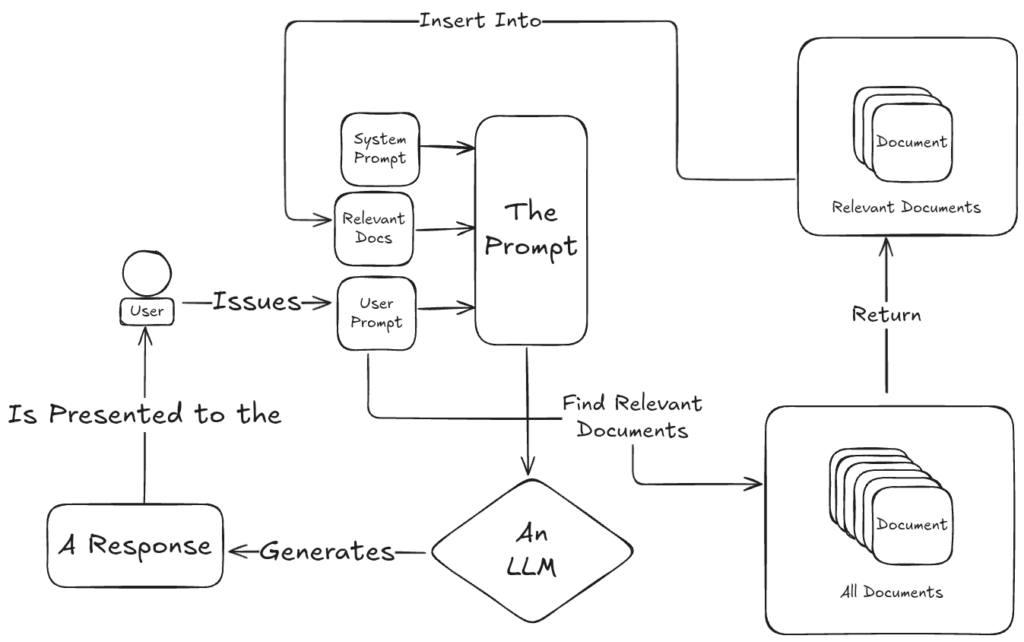
A well-formed prompt in a RAG system typically has three parts:
- System Prompt: A behind-the-scenes instruction set that defines how the AI should behave.
- Background Material: The retrieved, relevant documents.
- User Prompt: The actual request made by the user.
That background material should be formatted for clarity. That can mean a lot of things, maybe it’s grouped into bullet points, organized by tags, or even transformed into structured markdown. The critical thing is, even though LLMs fundamentally operate on unstructured data, a little white space induces just enough structure to help the system along.
What Do We Mean by “Relevant”?
Finding the right documents is one of the hardest, and most important, parts of any RAG system.
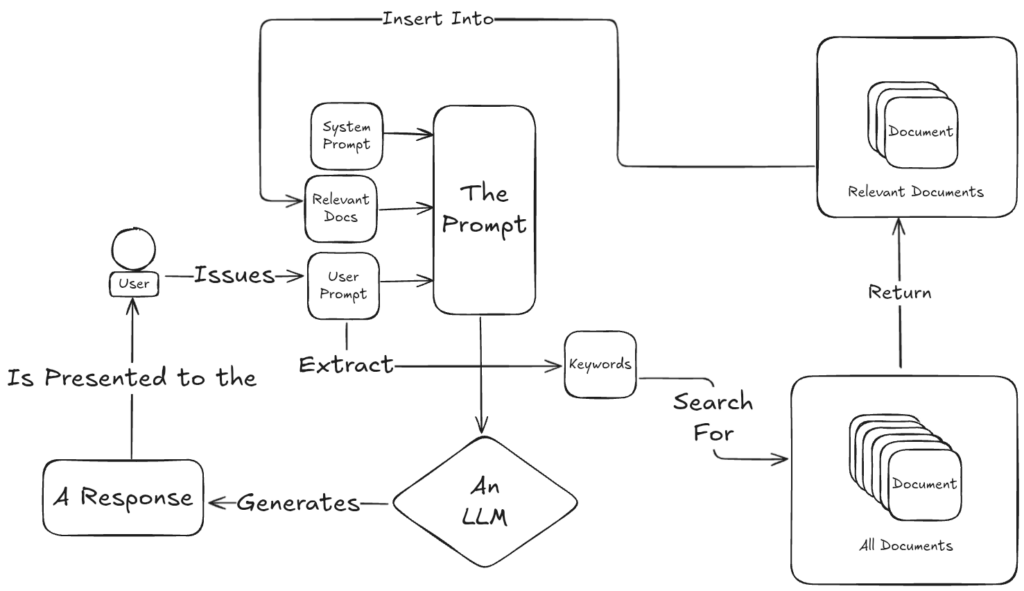
There are lots of ways to do it. Some methods are traditional, things like keyword search or TF-IDF (term frequency, inverse document frequency) scoring, as shown in the figure above. Others lean on more modern techniques, like vector embeddings that measure semantic similarity rather than literal or fuzzy word matches, as shown in the figure below.
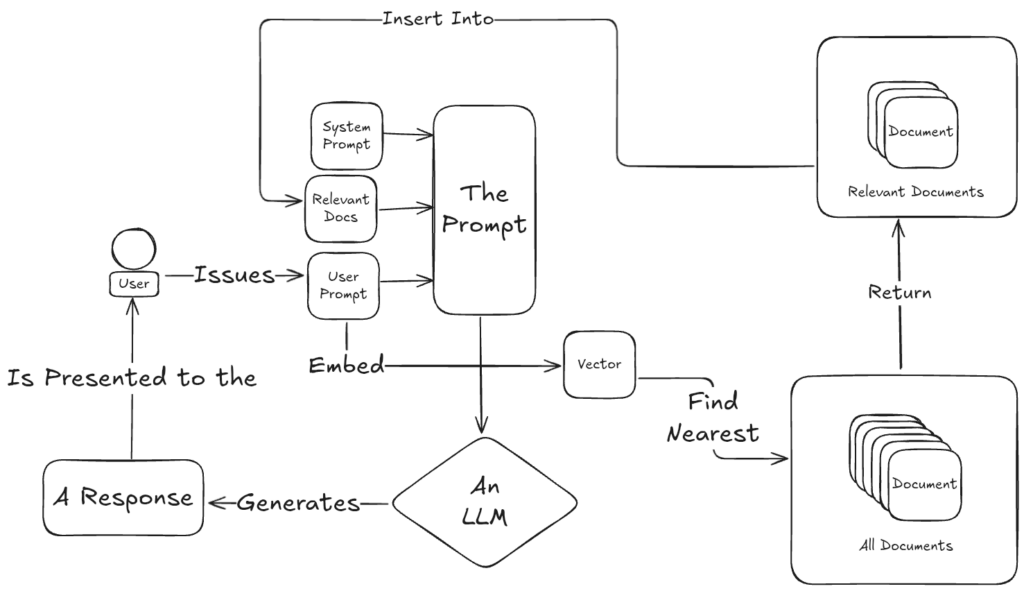
Regardless of how it’s done, the core idea is the same: from a sea of documents, surface only the ones that help answer the question. This is the “retrieval” in Retrieval Augmented Generation, and it’s where a lot of the real engineering work lives.
Where Custom RAG Work Still Matters
So if RAG is so well-documented, so standardized, so commodified, why not just buy off the shelf? What makes it worthwhile to build a bespoke system?
Here’s when it makes sense:
- You have sensitive or proprietary data that can’t be pushed through public APIs.
- You need higher accuracy and control than off-the-shelf tools provide. This is especially prevalent in domains where the cost of failure is high, generally measured in lives or livelihoods.
- You’re working in a niche domain where general-purpose models struggle to reason correctly. Think about the highly specialized language of medicine, aircraft maintenance, or any domain where language is highly specialized to concisely and exactly convey a nuanced idea.
When those conditions hold, there are three main areas where we roll up our sleeves:
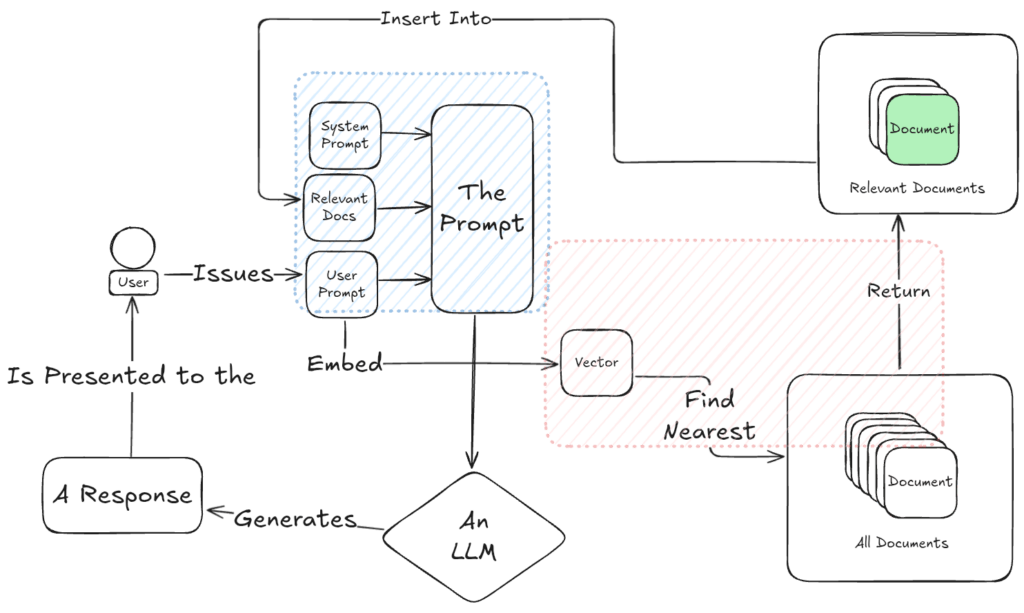
Retrieval Logic (the red box)
How you define “relevant” varies wildly depending on your data, your use case, and your expectations. Fine-tuning retrieval strategies, especially hybrid ones that blend traditional and semantic techniques, can dramatically improve outcomes.
Prompt Engineering (the blue box)
Once you’ve got the right context, how you hand it off to the model matters. That means shaping prompts in a way the model understands, structuring information for clarity, and sometimes even interleaving user questions with supporting material.
Document Structure (the green box)
This one’s subtle but huge. The word “document” can mean a lot of things. It could be a tweet or a forum post. It might be a paragraph, or a whole essay. Documents could naturally be interpreted to mean a 200-page PDF. For a RAG system to work well, the definition of document needs to align with the prompts the user is likely to submit. Like we said, the devil is in the details.
Ideally, the document is a self-contained chunk of content that contains all (and only!) the information needed to address a query that the user has. This definition is, unfortunately, kind of hard to nail down. It’s going to depend on domain, and to some extent, user.
What’s the smallest unit of information that makes sense on its own? That’s your “document”—and defining it properly is foundational to a good RAG implementation.
Why We Invest in This
Despite the maturity of the ecosystem, we continue to build RAG systems because they’re often the right blend of power, flexibility, and practicality. They let you avoid full model fine-tuning (which is costly and increasingly impractical), while still giving you meaningful control over outputs and accuracy.
And for teams working with real-world documents such as policies, procedures, engineering standards, client communications, it’s one of the most grounded and reliable ways to apply LLMs in production.
If you’re exploring how to use AI to make better use of your internal knowledge, or just wondering whether RAG is a fit for your business problem, let’s talk. We’re happy to help you sort through your options, whether you build with us or not.