

Introduction
The past few years have included rapid advancements in the field of artificial intelligence (AI). These advancements are particularly demonstrable in the natural language processing (NLP) domain. Newer transformer based models have demonstrated remarkable capabilities in generating human-like text, summarizing text, and answering questions. This new capability has captured the public interest with chatbots and, more recently, autonomous agents.
Before getting into the specifics of those use cases, though, let’s take a look at how we got here.
The Transformer Revolution
The big shift enabling recent developments was the transformer architecture. Transformers are a type of model dealing with sequences.
There are plenty of resources if you want to really get into the detail of the transformer architecture. At a high-level, though, the transformer architecture was introduced 2017 in the paper “Attention is All You Need”.
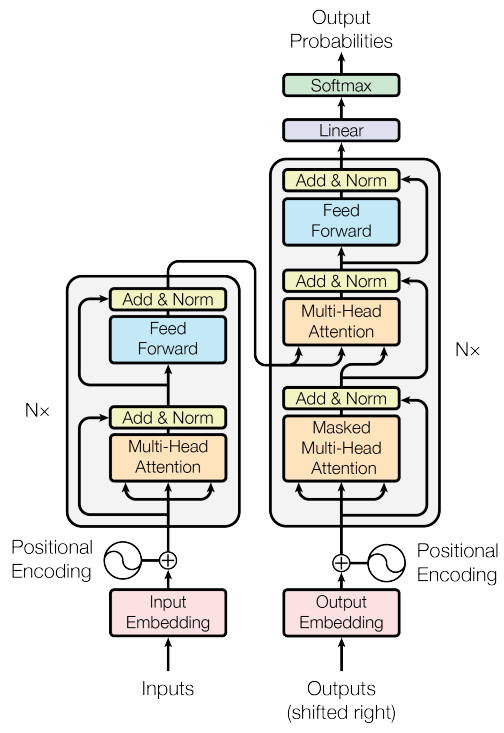
The key elements documented in that architecture are self-attention, parallelization, and scalability. This combination enabled significant improvements in NLP tasks.
Self-attention mechanism: The self-attention mechanism is at the heart of the transformer architecture. It allows the model to weigh the relative importance of different words in a sequence, providing context-aware results. This mechanism allows the model to capture long-range dependencies and complex relationships between words.
Parallelization: Other neural network architectures such as recurrent neural networks or long short-term memory networks must process inputs sequentially. Unlike those models, transformers do not have recurrent connections. This allows them to process input sequences in parallel, leading to faster training.
Scalability: Transformers are a highly scalable. This applies both to the number of parameters in the model and the size of the dataset on which they are trained. A general strategy for better performance has been to increase both of these sizes as models have evolved.
Additional Transformer Model Capabilities
The recent transformer models also have demonstrated a couple of capabilities that have further enhanced the perceived performance of outputs from the models.
Transfer learning: Transformer models have been successful with transfer learning. With transfer learning, a pre-trained model is fine-tuned for a specific task using a smaller labeled dataset. This enables task-specific results with NLP tasks, such as sentiment analysis or summarization, without the need to build task-specific architectures.
Multi-task learning: Transformers can be trained to perform multiple tasks, allowing knowledge from one task type to improve the performance on others. This can lead to more efficient learning and better generalization.
GPT
So, what exactly is “GPT”? The acronym stands for “Generative Pre-Trained Transformer”. Breaking that down:
Generative: In the context of AI, “generative” refers to models that generate new data based on patterns learned from the training data. Generative models create outputs that structurally resemble the training data. For example, GPT language models generate human-like text by learning the structures and patterns of language from large amounts of text used in training.
Pre-trained: Pre-training is a modeling technique where a model is first trained on a large amount of unclassified data. This training allows the model to learn about structure, features, and patterns. This combines with transfer learning wherein a smaller amount of task-specific data can be used to fine-tune a model towards a specific task.
Transformer: This is the transformer architecture described above.
Model Proliferation
While GPT-3 was the model to first capture the public interest (notably through the ChatGPT interface into that model), many other transformer models have subsequently been released. Browsing through the list at Hugging Face shows how many readily available models exist and provides a sense for how rapidly development and fine-tuning of models is occurring.
Completion and Chat Capabilities
In the next post, we’ll look at how these models enable text completion and chat capabilities.
Unlock the Power of AI Engineering
From optimizing manufacturing materials to analyzing and predicting equipment maintenance schedules, see how we’re applying custom AI software solutions.