

Communicating with computers is difficult, as anyone who has used one can attest. The burden is on the individual to clearly communicate with the machine. But what if computers could understand the way we speak naturally? This isn’t just about programming. It’s about all the data that’s stored, not in any machine code, but rather in natural language. Stories, articles, tweets, posts: they are all useful data waiting to be explored. So, if we want to use it, we need to be able to communicate the data to machines.
That’s where Natural Language Processing (NLP) comes in. NLP is the study of a machine’s processing (understanding) of natural language. Seems pretty sci-fi, right? If humans haven’t even mastered the process of language learning, how could machines? Lots of research and attempts to model speech! It’s not perfect, but that doesn’t mean it’s not useful.
One common usage of NLP today is text classification. When someone has a lot of text data, it is useful to group similar pieces together.
Think of support tickets. People often will have the same issue, but every person still needs help and will submit their own ticket. This generates thousands of similar and completely different tickets. Without any processing, it looks as though there are thousands of issues; but by clustering tickets together, a more digestible picture forms.
This problem clearly requires understanding the text of every ticket, right? Well, first, let’s take a step back and explore what NLP is.
What is NLP?

Many different tasks need NLP; however, each one has different end goals. Is solving the entire problem from question to chatbot all NLP? Is going from help tickets to groups by topic all NLP? These two things have completely different components. One needs to group texts by content, and another needs to generate responses based on a topic. So, how can two tasks that are so different be addressed by the same techniques?
Text, speech, language; whatever you want to call it, is characters and data. NLP is about turning that meaningless data into useful information. Then, that information can be analyzed or used in different algorithms.
There’s no end-to-end pipeline outlining how to solve all problems. If there were, there would be way too many, given the unique features of every problem. Instead, NLP is a toolkit with lots of options that each take raw language in and then give a new output that’s more informative. Or it takes a task in and outputs newly-formed language.
Even then, it’s more than tools thrown haphazardly in a box that people dig through and experiment with. There’s an organization that outlines the goal of each set of tools.

In NLP, the tools, or techniques, are organized by how deeply into language they delve. Whether it’s looking at words, structure, or meanings, every category has its own set of tools developed to help.
It’s a confusing concept at first, to think how sometimes you only need to look at structures of words, and other times you need to dive into “meaning”. So, let’s return to text classification and see how this works.
Text Classification
How do we classify or group text?
Clustering and classification are classic machine learning problems. There are many algorithms to solve this. So, you can stick text into an unsupervised machine learning algorithm and watch it group. Text is a series of characters after all. You’d find … something… but nothing remotely close to what you want. It doesn’t take into account anything about language. So, let’s take this a step deeper.
The most basic unit of understanding language is a word. (Actually, there is a smaller unit called a morpheme, but we’re going to put that aside for now.) Meaning is attached to every word. As a result, without looking at context or structure, there’s value found in examining what words are in a document and how often they appear.
“A big black bug bit a big black bear.”
“A bug became very successful after meeting a bear.”
“I ate pie.”
In these sentences, you can tell the first two sentences group together, and the third is separate. “bug” and “bear” appear once in the first two sentences and never in the last. Without thinking about whatever the sentence means, there is valuable information in looking at identical sets of characters and their frequency.
This forms the basis for a common text classification approach. Instead of throwing text data into a clustering algorithm, we turn text into a representation of the frequency of every unique word.
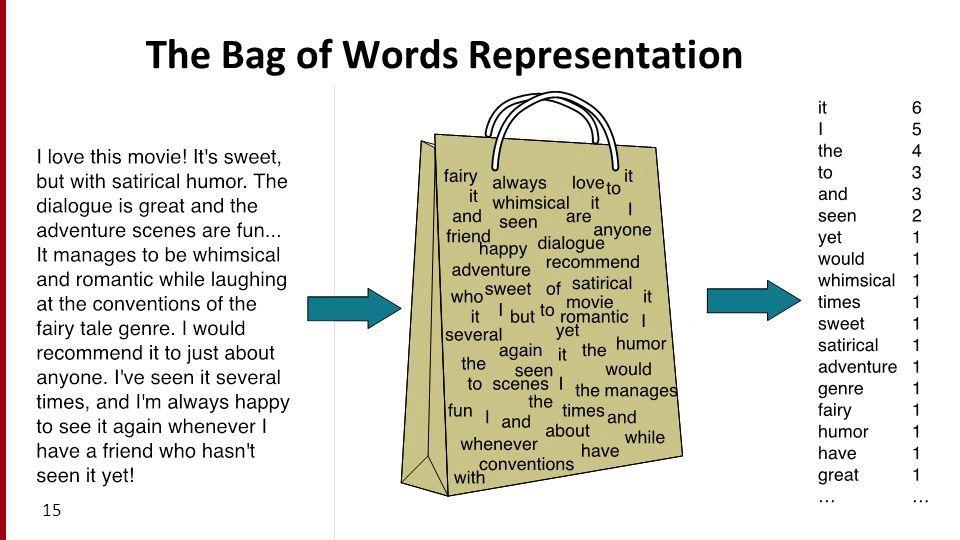
The technique of correlating documents with the frequency of unique words is known as using a bag of words. It associates each unique word in a collection of text to a number from 0 to the number of unique words. Then, for every number (unique word), the program tracks how many times that unique word appears. Thus, words change into numbers for traditional clustering and classification algorithms.
Admittedly, there are many other strategies to handle text classification. Creating language models and applying machine learning are two of those other strategies. Still, for the sake of looking at the language levels of NLP, we’ll be focusing on the bag of words approach.
This method of going straight from text to representations, while simple, has some flaws. Take the following for example:
“A big black bug bit a big black bear.”
“A big black bug bites a big black bear.”
“A big black rat bit a big black bear.”
Most likely, you’d want to group the first two sentences like before. They’re the same excluding the fact that one is present tense and the other is past tense. Yet, while the last is the same in the words used, it includes one big difference: “rat” instead of “bug”. From the standpoint of direct translation, both 2 and 3 are different from the first sentence by one word. Now we need to look at meaning, or at least part of speech right?
Nope! In this case, all we want to do is get the core of words. Instead of regarding “bit” and “bites” as different, we want to say they’re the same. So, in comes morphology.
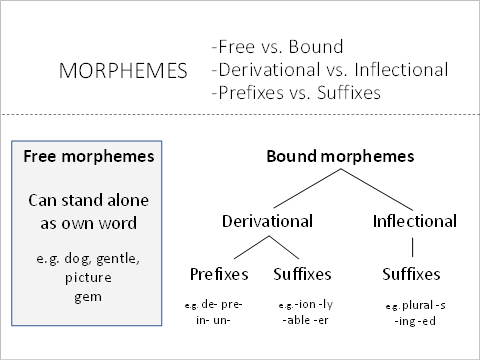
Morphology is the study of the structure of words or how smaller pieces build larger words. Luckily for us, there are rules studied by people that correspond to how smaller pieces build up different versions of a word. “Bit” and “bites” are two version of the same word, so, by applying the rules of morphology, they can be reduced to the same thing.
An easy example of morphology reduction is “walked”, “walks”, “walking”. We know -ed, -s, and -ing are common suffixes so we can chop then off leaving “walk”. (Stemming is the most common way of handling this).
By looking at words and understanding how words work, we can consider “bit” and “bites” the same. As a result, once again, we group the first and second sentence together and separate the third.
For many cases, taking the words and doing basic transformations is enough. Still, you might be thinking, what about words that are different but mean the same thing (synonyms)? What about times in which words are similar enough but not quite the same? What about times in which adding a suffix (and changing the part of speech) changes the meaning entirely?
Unfortunately, we can’t avoid looking at the “meaning” of words forever. But first, what is “meaning”? A “meaning” is an association of a word with other words. It’s a game of replacing one word with another until we get to the most basic word that encompasses all others. It’s a net of all words associated with that word. This is the study of semantics.
Semantics handles how different words relate. It considers words in isolation: synonyms and words of different similarity levels. That’s not all it does though. It also considers words in context. If “fly” is a verb, it means something going through the air; however, if “fly” is a noun, it’s this annoying black bug that won’t stop buzzing around your head. Syntax handles this. Syntax is the study of grammar and tagging parts of speech to build a better language model. Given the part of speech, one has a better idea of the exact meaning of a word.
But then, after applying transformations based on semantics, once again the clustering problem boils down to a new bag of words.
In every step, whether we need to handle an issue with morphology, syntax, or semantics, there are different tools and methods to approach it. There are rule-based systems that outline exactly how something should transform. But there are also machine learning strategies that handle the exact same issues. Every tool has its own drawbacks and advantages.
Conclusion
As you can see, NLP problems aren’t black and white. There’s no best solution. Instead, there are choices about how deeply into language a problem needs to go and what tool to use to handle it. It transforms unstructured data into information to be processed and it’s an area researched today. Regardless, if you’re interested in these levels of language, I’ll be releasing a series on each level including: how it’s used, the techniques handling it, why it’s complicated, and the current research. Otherwise if you’d like to create your own text classification software, here are some interesting guides.
- Document Clustering with Python
- IT Support Ticket Classification and Deployment Using Machine Learning and AWS Lambda
- Gentle Introduction to the Bag of Words Model