

Blog Post Written By: Lisa Lo
In our last (first?) NLP post, we explored Natural Language Processing (NLP). As mentioned, a great place to start the discovery of NLP is sentiment analysis since it’s a well-known and studied problem, but also very useful. So, today we’ll be going over an overview of sentiment analysis and how it’s done.
Overview
What even is sentiment analysis?

Sentiment is how someone feels about a situation: an opinion. So, as the name suggests, sentiment analysis is determining how people feel from text.
“Wow, I had such an amazing time and I’d be so happy if you did it again!” 😊
“Wow, that was… something. Definitely would not recommend or do again.” ☹️
The first obviously has a positive sentiment, and the second is clearly negative; however, this isn’t so obvious to computers. Remember, computers only know what we tell them.
Sentiment analysis tasks tend to be grouped in a few different levels: detecting positive or negative sentiment, emotion identification, and aspect-based sentiment analysis. Detecting positive or negative sentiment, as shown above, is generally what sentiment analysis refers to. Emotion analysis goes beyond the positive and negative to further identify emotions, and afterward, aspect-based analysis takes the first two levels and figures out what specifically the sentiment refers to. For example, consider:
“The car was cool, but the van was not so much.”
Aspect-based sentiment analysis associates positive with the “car” and negative with the “van”. Regular sentiment analysis returns either the entire statement is positive or negative, or it returns an overall breakdown of 50% positive, 50% negative.
At first, while interesting, it doesn’t seem very practical. After all, we intuitively know what’s positive or negative. For a single line, it’s not that useful. But think about people. People love to talk, gossip, announce their achievements, and verbally tear down whatever they dislike. Reviews, social media, blogs, etc. is more than text: it’s data. It’s data that’s readily available if it can be processed efficiently. Reading everything by hand would take centuries, but a computer is significantly faster.
Perhaps you run a business. Most likely, you want to know how your product is doing. You can use sentiment analysis on social media and reviews to see whether people like your product or not. You could even keep track of similar products and use sentiment analysis to scope out the competition and the market demand. Knowing how people feel is a very powerful tool.
If you don’t run a business, maybe you’re curious how people feel about an event like a rocket launch or an election. If you want to know how people feel about elections, take Twitter posts and filter them on those topics. If you want to see how people feel about ideas, products, fads, and so on, web scrape the internet (likely social media) and look at the results using sentiment analysis.
So, from here, let’s dig a little deeper in how sentiment analysis works and the various approaches to it.
Approaches
For nearly every NLP problem, there are several different approaches that fit in four major categories:
- Rule Based
- Statistical
- Supervised Learning
- Deep Learning
Sentiment analysis follows this same pattern. Every method either reaches a different level of language depth; or trades between human effort and potential control giving pros and cons to each. We’ll be going through rule based, supervised learning, and deep learning.
Rule-Based Systems
Rule-based systems may seem antiquated; however, they have major advantages, most notably, control and utilization of human knowledge. These systems are carefully crafted by linguists and domain experts to map how we think to the computer.
Read the following sentence:
“That video had information. It brings up points.”
Compare it to:
“That was a very informative video. It brings up many important points.”
While the sentences are nearly identical, there’s one key thing that was added: adjectives. That changed the sentence from an objective sentence to a subjective positive sentence.
Something that’s objective is essentially a hard truth or facts. This is normally the information contained in the nouns and verbs of sentences. They display what happened without any feeling involved.
Something that’s subjective involves someone’s feelings. It’s a statement that could be disputed. That’s where all the adjectives and adverbs come in. They provide descriptions. They don’t always indicate how people feel, but they can.
Take the following adjectives:
- Great
- Fascinating
- Cool
- Bad
- Ugly
- Smelly
Reading the first three, without knowing anything else, gives a good feeling. Similarly, the last three give a bad feeling. This is the basis of rule based systems.
We know which words have positive connotations and negative connotations; therefore, we can give each word a value. The more positive a word is i.e. great versus good, we can assign a larger number. Conversely, the more negative a word is —i.e., horrible versus bad —we can assign a larger negative value. Then, by looking at each word with a value assigned, we can add those values up and get a very basic idea of sentiment.
Of course, there are exceptions where considering adjectives on their own isn’t enough. For example, “great” most of the time is a positive thing; however, “great disaster” probably isn’t positive. (Admittedly, someone could actually mean it in a positive way, but that’s a whole other issue of how even humans can’t agree on the sentiment of statements all the time.) Some nouns have an implicit connotation to them, like “disaster”. So, in the case of “great disaster”, great increases the negative connotation. Given this information, another rule-based system may take nouns into consideration and make adjectives into multipliers for those values of nouns. Regardless, this begins to show the complexity of creating rule-based systems.
Rule-based systems require a lot of time and knowledge of language and that specific domain. People must either find all the relevant words or find a way to reduce all words into a smaller dictionary. They also need to decide what other features they want to take into consideration based on the domain. For instance, when people are texting or on social media, there are a lot of small patterns that indicate sentiment:
“THAT WAS SO GOOD”
“That was sooooooo good.”
“That was so good!”
“That was good.”
While capitalization, punctuation, repeating letters, text speak, and emojis aren’t, strictly speaking, words, they all contribute to the sentiment of a text. As a result, they can be another pattern to assign a value to.
In summation, these systems look at the content of text, convert its pieces based on the rules, and add up all the values. The one flaw of only adding numbers is getting a lot of arbitrary numbers. Some sentences may be longer or shorter, resulting in larger or smaller sums that are difficult to compare. That’s why the sum is normalized, or reduced to a smaller range between -1 and 1. This eliminates the effect of length. Now, across all instances, it’s clear to see what is more or less positive and negative.
Rule-based systems take into account many things that other strategies will not. It also has benefits in explainability and improvement. We know exactly why we are getting the results we get. We know what rules, words, and phrases we’re using, so if someone finds a new pattern or a new phrase becomes popular, we can add it to our dictionary of “words” or “patterns” to values.

This also has a drawback of language constantly evolving. The meaning and connotation of words changes. All of this leads to needing a lot of human effort. Experts (or college students) need to come up with rules, study language, and make conclusions about what indicates what. They need to create corpuses of text to value mappings. They need to keep it updated to the current meaning of words. As a result of everything, rule based systems are limited to what people know and recognize.
This leads us to conclude that, for small systems with small sets of potential words and phrases, rule based systems are very effective. We can map everything out. Similarly, if we have lots of linguists who want to utilize their knowledge to create a precise system, then rule based systems have great results. Practically, though, if we have all of the English language as possibilities and not a lot of time or space, most of the time, using supervised learning or deep learning is a better choice. Still, if there’s many edge cases and varieties of words that each contribute meaning like on social media; those pieces are difficult to capture in other techniques.
Supervised Learning
Most people doing sentiment analysis will start with supervised learning.
One important point right off the bat is: for supervised learning to work, we need a set of labeled data. In other words, we need a set of data with thousands of samples that have been labeled as positive, negative, or neutral. We also want this training data to be as similar to what you want to perform sentiment analysis on as possible. If we want to do sentiment analysis on Twitter and train on movie reviews, we would miss common terms that people use in text speech that are important for determining sentiment. This will become clearer why it’s important as we go through how it works.
There are many sentiment analysis sets out there for experimenting, but if you’re a company that has a specific task, then it’s best to use data representative of that task. This does mean taking up more human labor in the beginning, but ideally, it’d pay off in the future.
Supervised learning is very similar to the rule-based systems in that it again focuses on words. The difference, though, comes in where instead of assigning values to each word, we look at the frequency of words, or how many occurrences of each word there are. Then, looking at the more common words, we take that as our feature set that we stick into a classifier.
In other words, we take a certain number of the most common words and then map each piece of text to how many times each common word occurs. We’re creating a bag of words using morphology and syntax techniques to reduce the vocabulary of words. Afterward, we tell our classifier: “These are sets of features (words) and whether each set (piece of text) is positive or negative. Learn which features(words) are more indicative of a positive or negative statement.” From there, that information is stored and when we pass a new piece of text in, it matches the words of the text to the words it has seen to determine whether the new text is more likely positive or negative. If the words in our text don’t match the feature set (words that the sentiment analyzer uses to classify positive or negative), then the sentiment analyzer is not going to work. This brings us back to why it’s important to use similar training data to what you want to perform sentiment analysis on in the future.
In a way, it’s like rule-based systems, except instead of having humans assign values to each word, we send it to a classifier to determine whether a word belongs in the positive, negative, or neutral category. It takes care of a lot of the human effort required for rule-based systems; however, it still has downsides.
If someone asks, we can’t say why a word is associated with positive or negative sentiment beyond it’s a common pattern. If we have irrelevant or incorrectly labeled training data, then we’ll continue to propagate that incorrectness or have completely random results.
Beyond the common issues found in all of machine learning, integrating human knowledge is significantly more difficult. Capitalization, punctuation, and all of those weird patterns mentioned in the rule-based systems are much more difficult to capture. There are still some things that can be done to help, such as using human knowledge in the preprocessing step, but it’s still not as precise as rule-based systems. Normalizing words (changing synonyms or things we know mean similar things to the same word) and removing stop words are good first steps to try to handle this issue.
All in all, in most cases, supervised learning is a great place to start sentiment analysis. With good training data, supervised learning with very little work can get around 70-80% accuracy without even needing any knowledge of language. However, the more precise we want to get, the more difficult it becomes to capture more complex features of language with only supervised learning.
Deep Learning
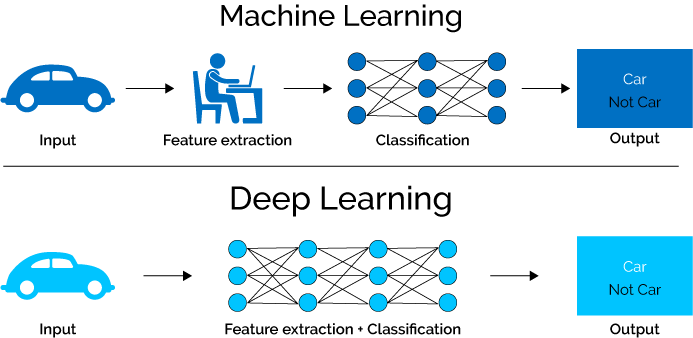
Both rule-based and supervised learning use the same method of looking at words in isolation. For most cases, this is enough; however if we want to get even more accurate, we need to take into consideration context and phrasing. We need more information about the structure of the sentence rather than what words were included arbitrarily.
“Not that bad”
“It was neither good or interesting”
Depending on the rules and training data would likely be considered negative in the first case and positive in the second. “Not” and “Bad” are more negative inclined words; although overall, as a phrase, it creates something positive. Similarly, “good” and “interesting” are positive inclined words, but with “neither” in front, it becomes negative.
There are also issues such as irony, sarcasm, and context. In these cases, the order of the words, and pieces around each word all matter and change the meaning. There’s no direct translation, and even in humans, it can be hard to detect over text.
This is where deep learning comes in. Adding deep learning allows more structure to be taken into account. For instance, long-term dependencies, i.e., where one part of a sentence or paragraph affects something later on. Similarly, complex word-embeddings, i.e., tracking that “clever” and “smart” are more closely related than “clever” and “book” are, are encapsulated using neural nets. Deep learning gives programs the ability to have “memory” and create models of the language.
There are many different deep learning algorithms that are useful for sentiment analysis. Convolutional Neural Networks, Long Short-Term Memory Networks, and Memory Networks are a few of many deep learning techniques used to solve complex problems with sentiment analysis.
To learn more about it, check out this paper which gives an overview of the deep learning techniques.
Detecting things like sarcasm, complex sentence structures, irony, common phrases, and sentence structures all require deep learning to model the language and then conclude whether the output is positive or negative. Given the number of choices of techniques, it can definitely be harder to build up the pipeline of a sentiment analyzer. There are complex choices of representation and where to use what technique; however, when utilized properly, it can reach over 85% accuracy.
Conclusion
“I love sarcasm.”
Sentiment Analysis is a common and fascinating problem. Just like many other problems, getting the first sentiment analyzer with 60-70% accuracy is fairly simple; however, the higher the accuracy one wishes to go, the more effort is required due to edge cases. One important thing to remember, though, is that humans themselves only consistently agree on sentiment approximately 80% of the time. As a result, getting to 80% is pretty good!
100% will always be impossible given that humans can’t always agree 100% of the time, but that doesn’t mean there’s no research and progress to be made either. There are cases in which humans will intuitively know positive or negative that machines will not recognize; therefore, research continues to try to decrease these instances.
So, with this basic knowledge of sentiment analysis in hand, it’s up to you what system you wish to use. For specifics on how to start, soon we’ll be releasing an in-depth guide walking you through your very first sentiment analyzer!